
ByConity x CubeFS: 万亿级OLAP平台云原生构建方案
本文涉及开源组件
CubeFS | https://github.com/cubefs/cubefs |
CubeFS 是新一代云原生存储产品,目前是 云原生计算基金会 (CNCF)托管的毕业开源项目, 兼容 S3、POSIX、HDFS 等多种访问协议,支持多副本与纠删码两种存储引擎,为用户提供多租户、 多 AZ 部署以及跨区域复制等多种特性,广泛应用于大数据、AI、容器平台、数据库、中间件存算分离、数据共享以及数据保护等场景。现由 OPPO 主导维护。
ByConity| https://github.com/ByConity/ByConity |
ByConity 是基于 ClickHouse 内核研发的开源分布式的云原生 SQL 数仓引擎,擅长交互式查询和即席查询,具有支持多表关联复杂查询、集群扩容无感、离线批数据和实时数据流统一汇总等特点。由字节开源与维护。
关于 MetaApp
MetaApp 是国内领先的游戏开发与运营商,专注移动端信息高效分发,致力于构建面向全年龄段的虚拟世界。截至 2023 年,MetaApp 注册用户已超 2 亿,联运合作 20 万款游戏,累计分发量过 10 亿,拥有千万日活 233 乐园、233 派对等应用
万亿级 OLAP 数据分析平台 Pandora 简介
随着业务的增长,精细化运营的提出,产品对数据部门提出了更高的要求,包括需要对实时数据进行查询分析,快速调整运营策略;对小部分人群做 AB 实验,验证新功能的有效性;减少数据查询时间,降低数据查询难度,让非专业人员可以自主分析、探查数据等。 为满足业务需求,早期我们基于 Clickhouse 实现了集事件分析、转化分析、自定义留存、用户分群打标、行为流分析、AB 实验等功能于一体的 OLAP 数据分析平台。
平台功能简介
· 事件分析:对收集到的用户事件进行灵活的筛选、分组、汇总。根据埋点数据进行筛选,做一些用户属性的分组或者是全局属性的筛选,查询完成以后进行数据展示,可按列按天展示。
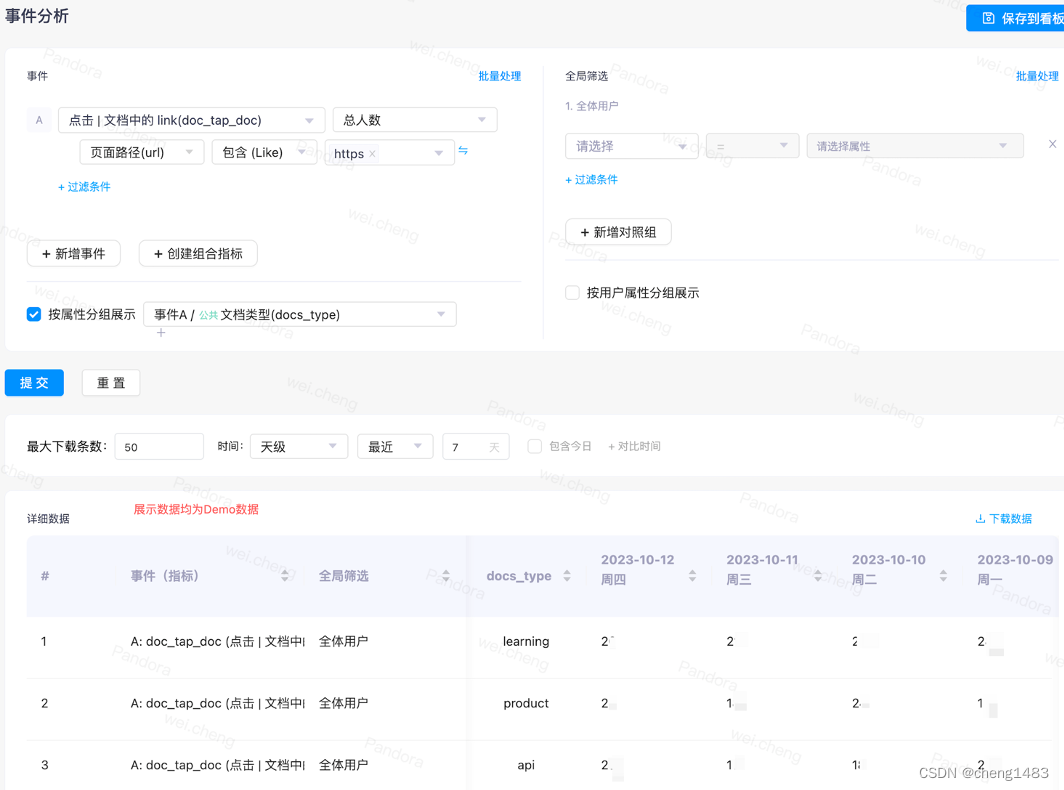
· 转化分析:分析用户使用产品的转化情况,即漏斗分析。根据开始事件和结束事件选定,查询具体时间内的转化。
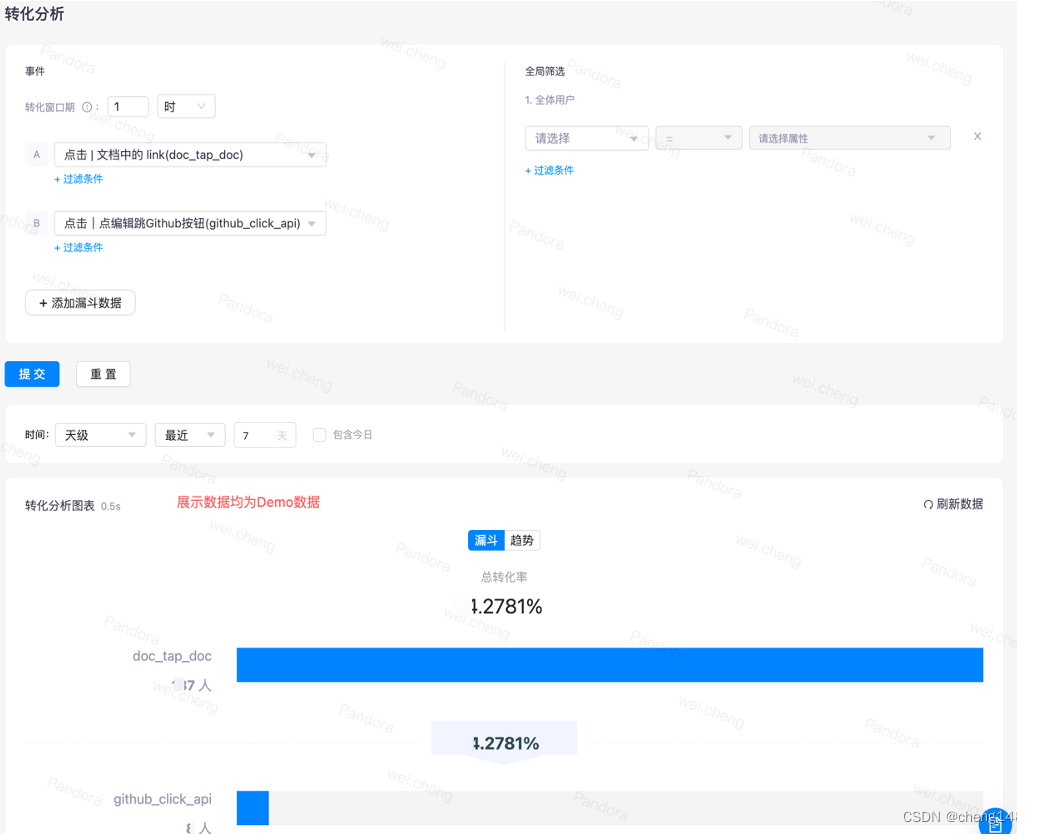
· 留存分析:分析用户在使用产品后再次回到产品的时间。根据起始事件、回访事件生成阶梯图。
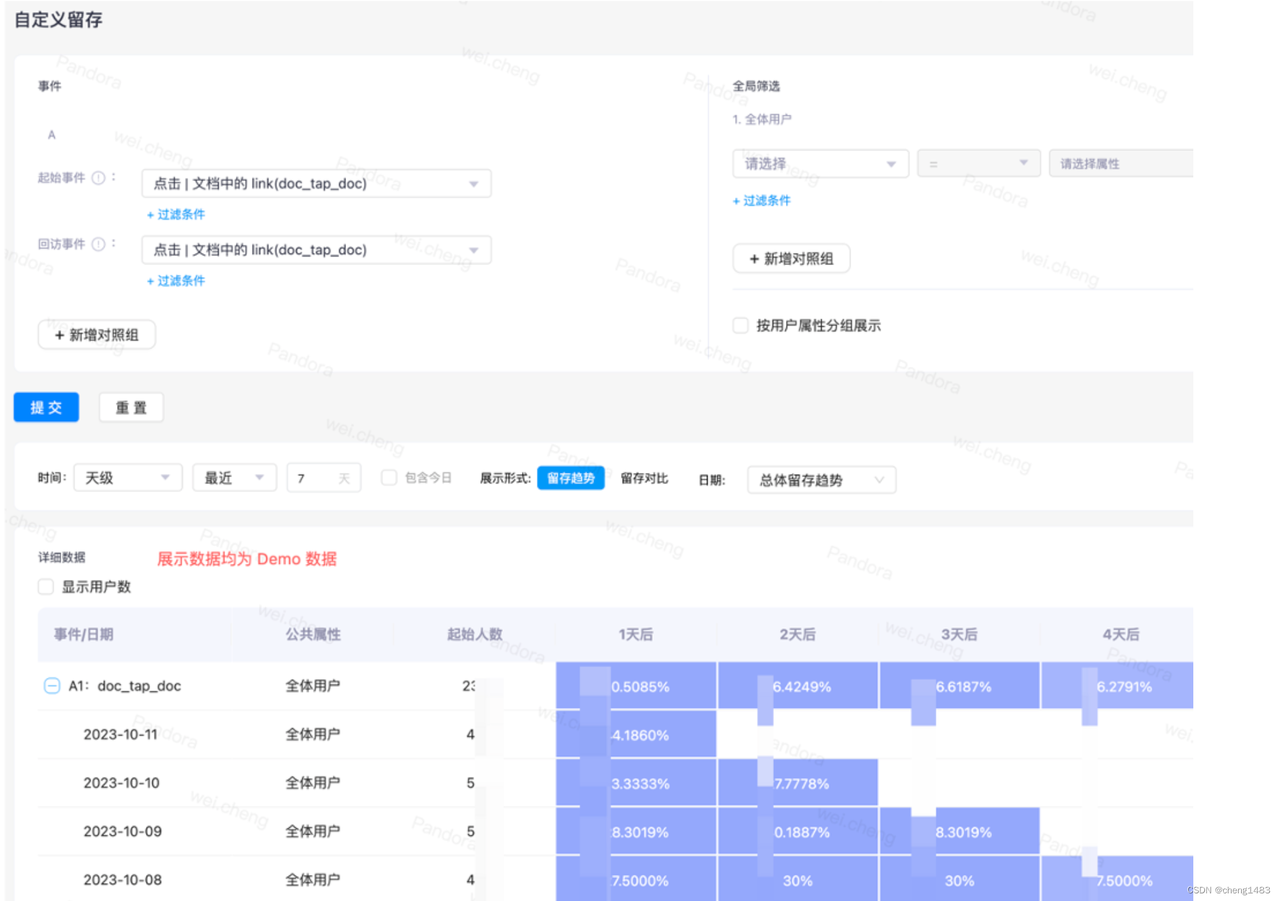
· 用户分群:用来对指定用户群体的数据进行过滤分析。根据条件将符合条件的用户筛选出来并进行分群,并根据分群结果查询对应指标,如停留时间、玩游戏的时间等,为业务提供辅佐。
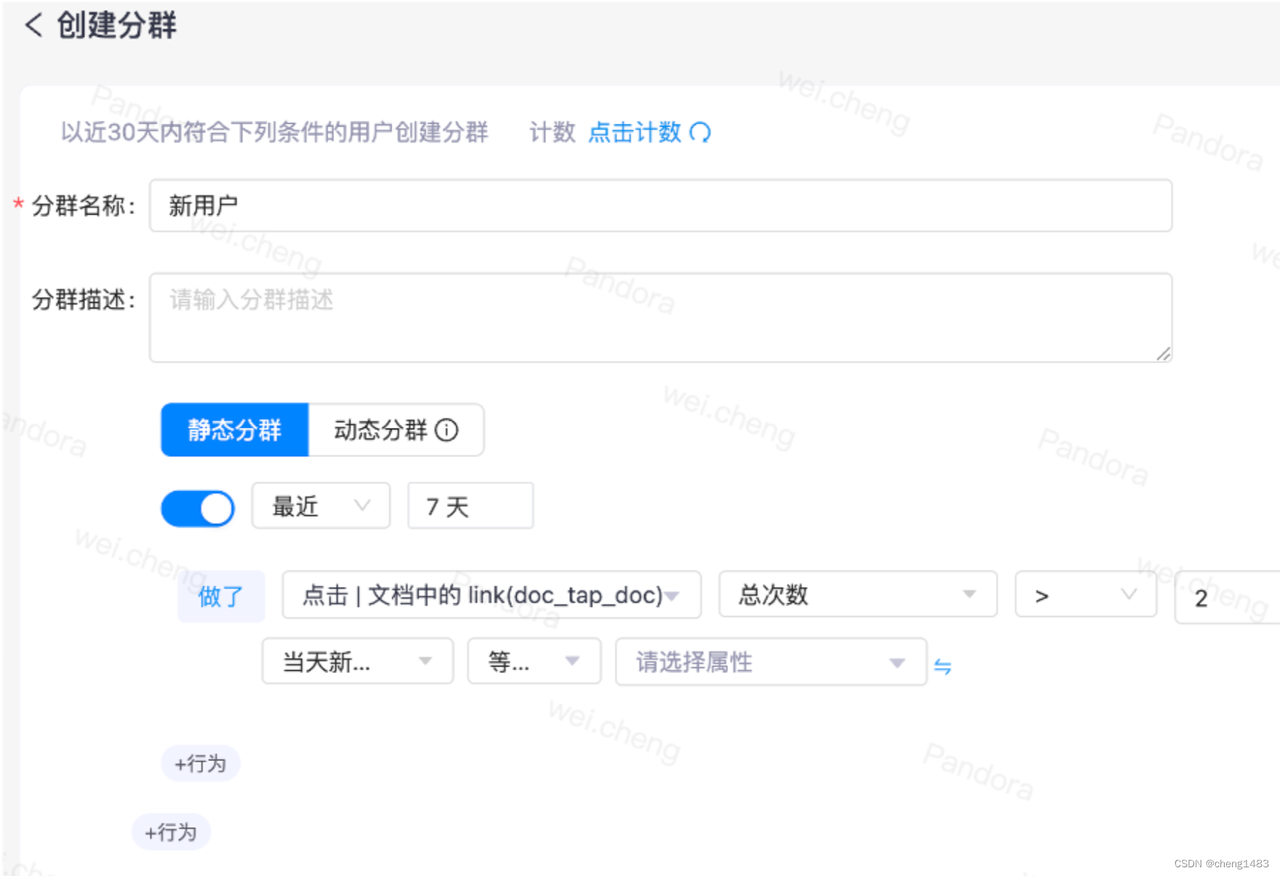
· 行为流:用来对单个用户的单个行为流进行分析。主要是用来查看某些用户的具体事件,如是否完整观看广告。
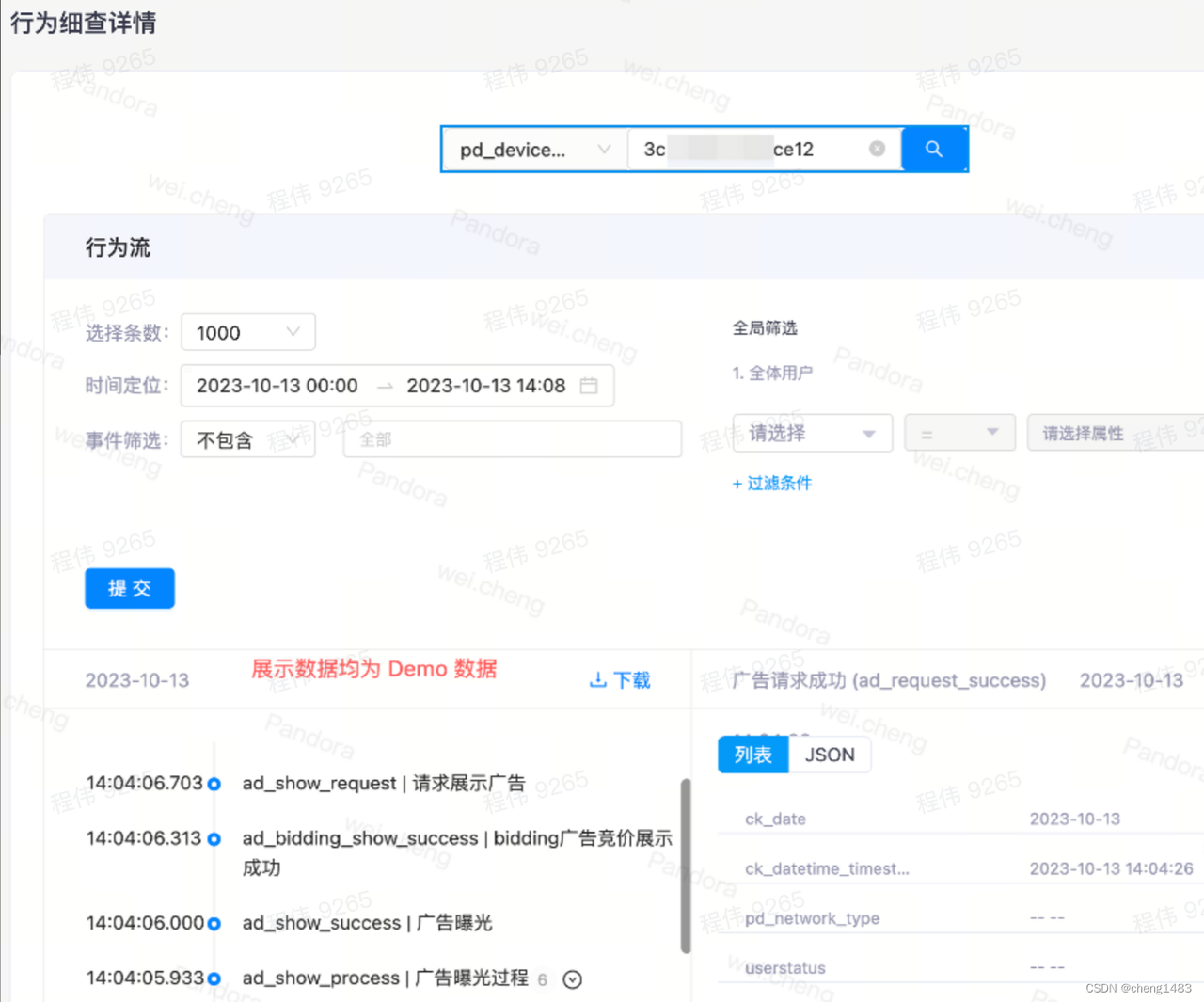
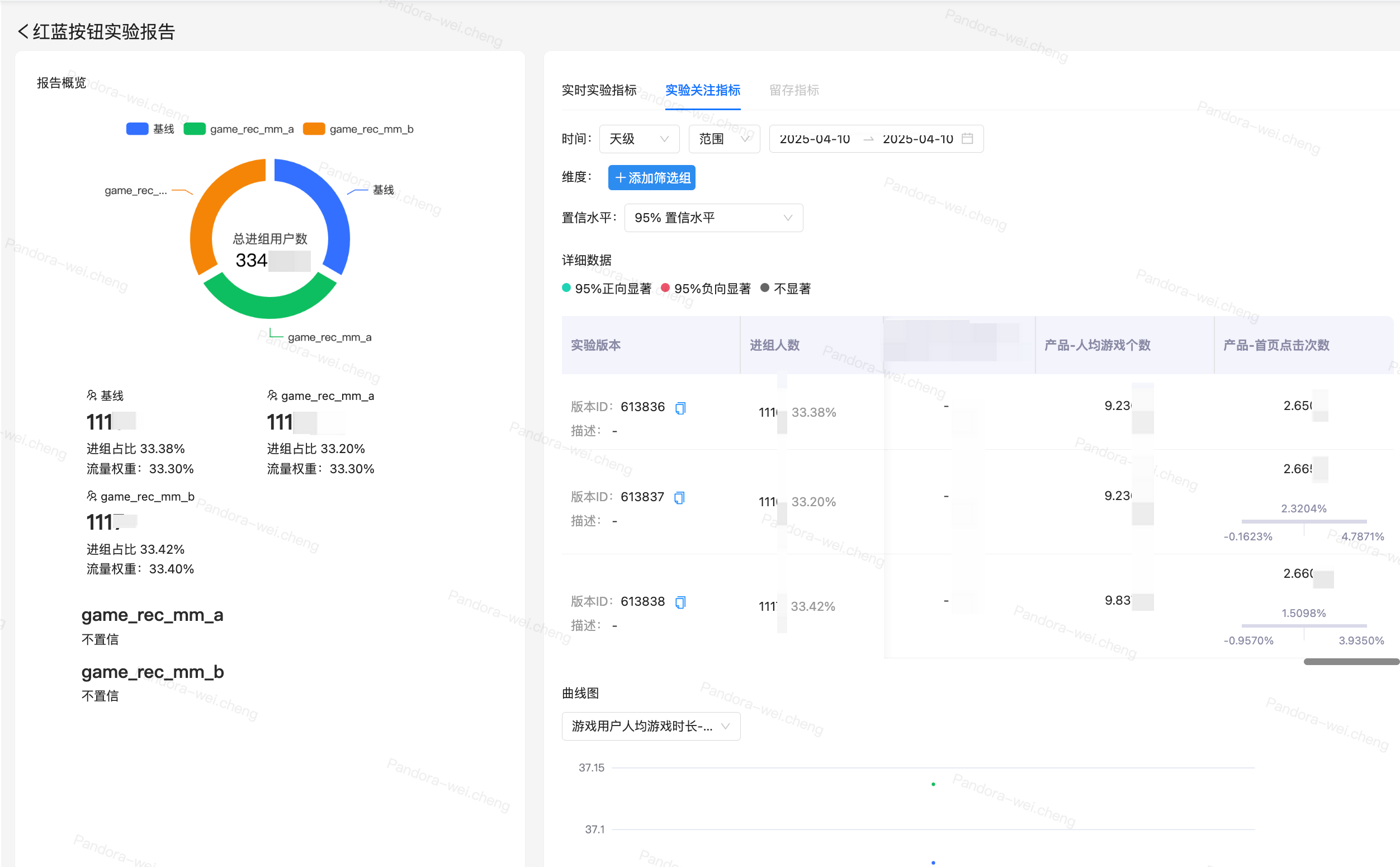
· AB 实验:从线上取一小部分流量进行新功能的测试
平台数据流向图
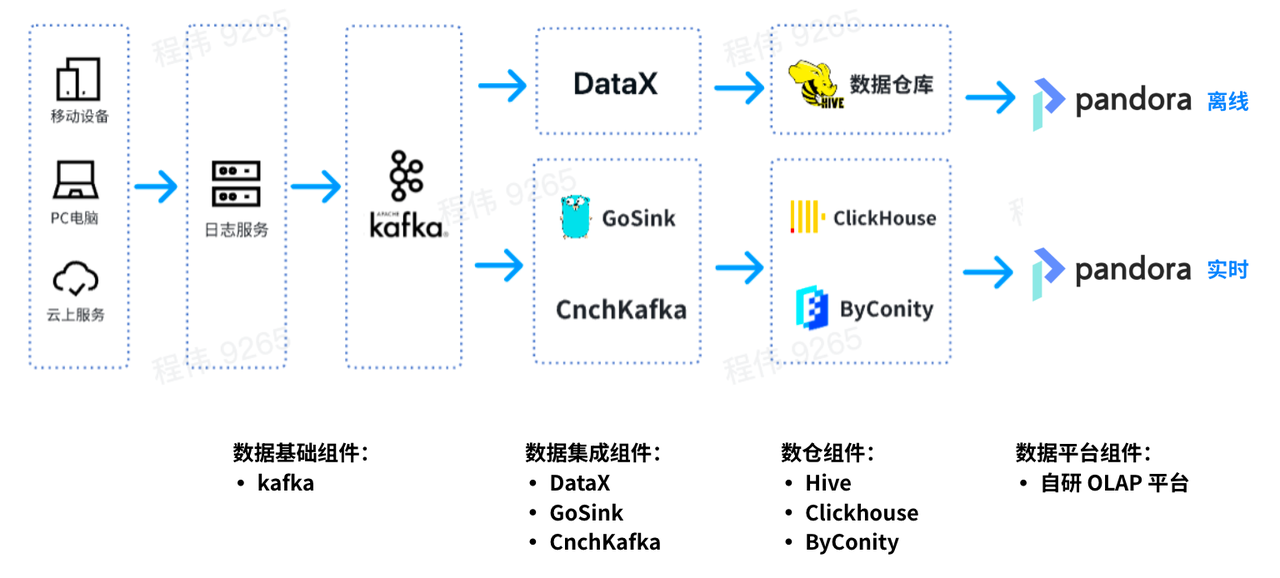
这是一个典型的 OLAP 的架构,分成两部分,一部分是离线,一部分是实时。
在离线场景中,我们使用 DataX 把 Kafka 的数据集成到 Hive 数仓,再生成 BI 报表。BI 报表使用了 Pandora 的 BI 报表功能 来进行结果展示;
在实时场景中,一条线使用 GoSink 进行数据集成,把 GoSink 的数据集成到 ClickHouse,另外一条线使用 CnchKafka 把数据集成到 ByConity。最后通过 OLAP 查询平台获取数据进行查询。
遇到的问题
数据量与业务情况:

业务高峰时,我们的应用埋了 1500+个埋点,产生的日志数据量一天将近有 400+亿条,未压缩前将占用 100+T 的存储空间。
由于业务的潮汐性,节假日业务量爆发式增长,工作日业务量平静的没有波澜。
我们将所有的埋点存在一个 Clickhouse 大宽表中,将近 3000+列。
随着使用量的增长,Clickhouse 很快就露出了问题:
问题一:读写一体容易抢占资源,无法保证读/写稳定
业务高峰期时,数据写入将大量挤占 IO 和 CPU 资源,导致查询受到影响(查询时间变长)。数据查询也是如此;
问题二:扩/缩容麻烦,周期长
· 扩/缩容时间长:由于机器在 IDC,属于私有云,其中一个问题在于节点增加周期特别长。从增加节点需求发出到真正增加好节点需要一周到两周的时间,影响业务;
· 无法快速进行扩缩容:扩缩容以后要重新进行数据分布,否则节点压力非常大;
问题三:运维繁琐,业务高峰期无法保证 SLA
· 常常因为业务的节点故障导致数据查询缓慢,数据写入延迟(逐渐从延迟几小时到几天的程度);
· 业务高峰期时资源出现严重不足,短期内无法扩容资源,只能通过删减部分业务的数据,为优先级高的业务提供服务;
· 业务低峰期时,资源大量空闲,成本虚高。虽然我们在 IDC,但是 IDC 的机器购买也受成本控制,且不能无限制的节点扩容,另外在正常使用时也有一定的成本消耗;
· 无法和云上资源进行交互使用;
解决方案
为啥选 ByConity
由于 ByConity 基于 Clickhouse 内核开发,兼容 Clickhouse 的 SQL,所以 ByConity 测试的成本最低,而且历经字节的生产考验,有字节作为背书,没有后顾之忧。
ByConity 的介绍:
ByConity 是基于 ClickHouse 内核研发的开源云原生数据仓库,采用存算分离的架构。两者都具有以下特点:
· 写入速度非常快,适用于大量数据的写入,写入数据量可达 50MB - 200MB/s
· 查询速度非常快,在海量数据下,查询速度可达 2-30GB/s
· 数据压缩比高,存储成本低,压缩比 可达 0.2~0.3
ByConity 拥有 ClickHouse 的优点,与 ClickHouse 保持了较好的兼容性,在读写分离、弹性扩缩容、数据强一致方面进行了增强。两者对于以下 OLAP 场景均适用:
· 数据集可能很大 - 数十亿或数万亿行
· 数据表中包含许多列
· 仅查询特定几列
· 结果必须以毫秒或秒为单位返回
在之前的分享中, ByConity 社区对二者从使用角度进行过对比 ,概括总结如下:
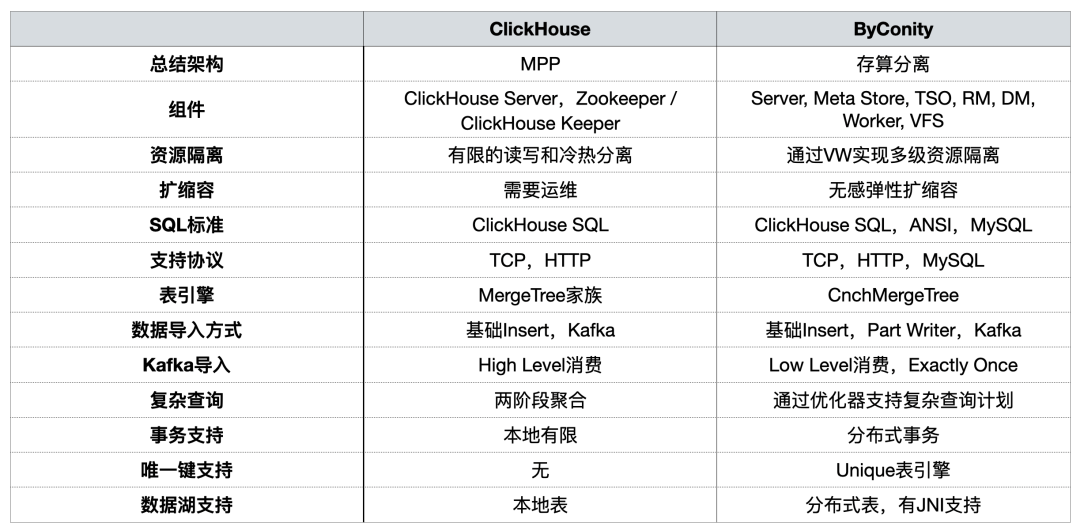
在 OLAP 平台构建过程中,我们主要关注资源隔离、在扩缩容、复杂查询,以及对分布式事务的支持。
为啥选择 CubeFS
我们选择了 ByConity 作为替换 Clickhouse 的组件,但是由于 ByConity 是存算分离的云原生架构,需要把数据存储到 HDFS/S3 中,选择一个 S3 存储就成了我们的主要目标。在对 minio、seaweedfs、juicefs 进行调研后最终还是选了 CubeFS。CubeFS 在 OPPO、京东等大厂生产中大量应用,稳定性成熟度更高。
CubeFS 的简介:
CubeFS(原名 ChubaoFS)是一款新一代云原生开源存储系统,是云原生计算基金会(CNCF)的毕业项目。该开源项目由社区和 OPPO 等多家公司共同维护和发展,持续在云存储、高性能计算等领域优化演进。
CubeFS 支持 S3、HDFS 和 POSIX 等访问协议,广泛适用于大数据、AI/LLMs、容器平台、数据库和中间件等场景,提供存储与计算分离、数据共享和分发等能力。可以快速、按需进行扩缩容。
CubeFS 由 元数据子系统(Metadata Subsystem) ,数据子系统(Data Subsystem) 和 资源管理节点(Master) 以及 对象网关(Object Subsystem) 组成,可以通过 POSIX/HDFS/S3 接口访问存储数据。
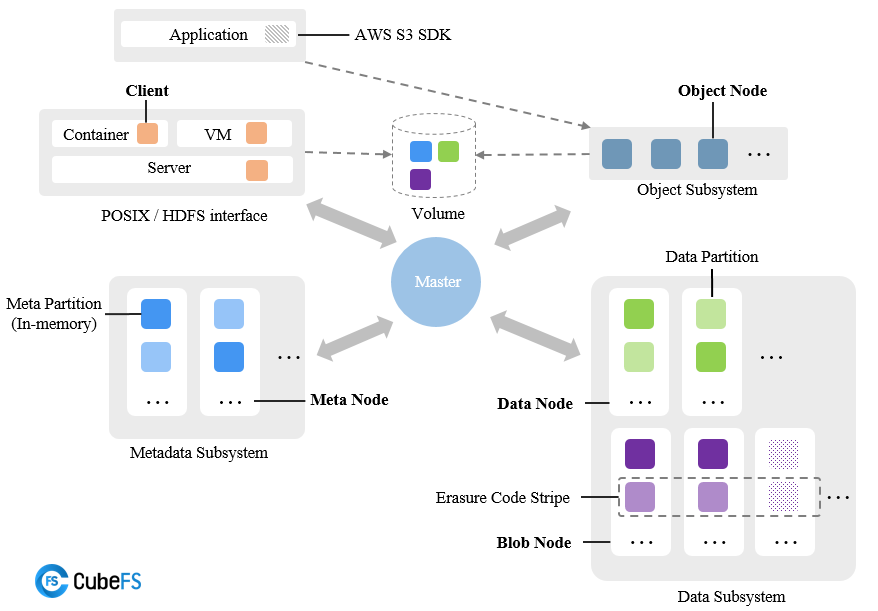
最终的组件图
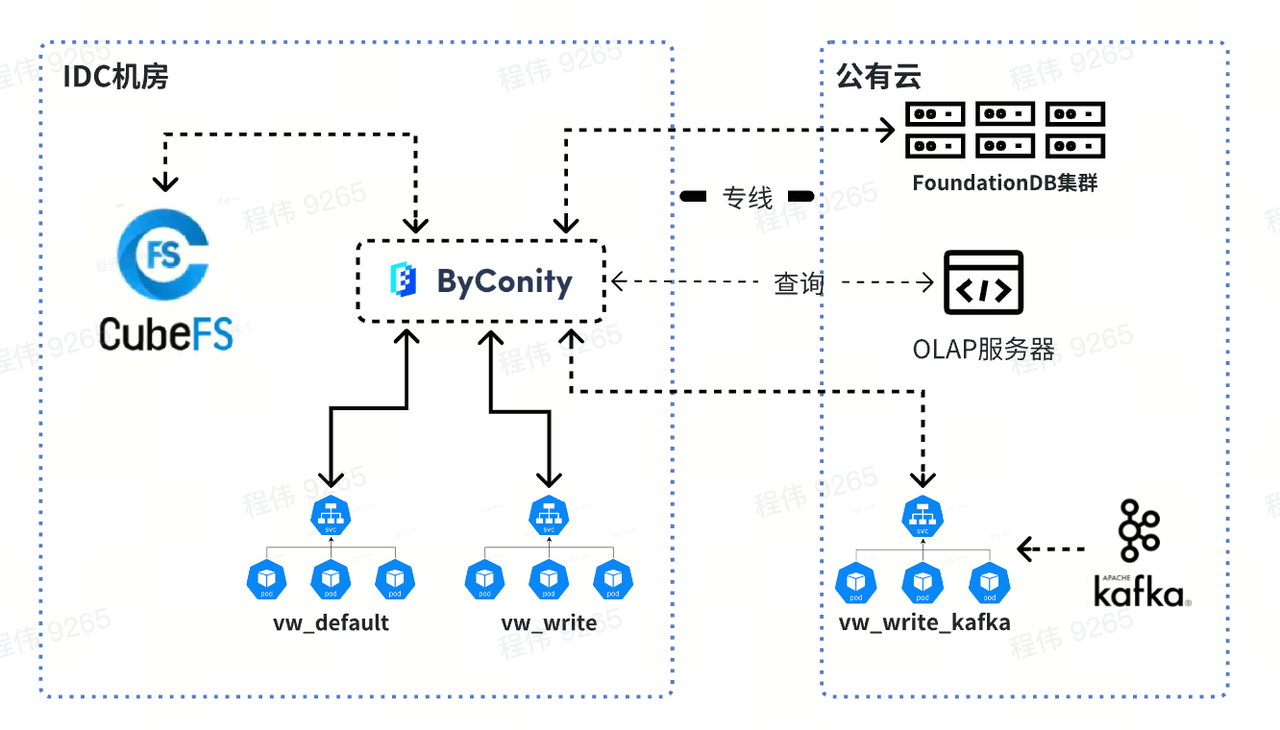
解决了哪些问题
首先,ByConity 读写分离计算资源隔离可以保证读写任务比较稳定。如果读的任务不够,可以扩展相应资源,哪里不够补哪里,包括使用云上资源进行扩容。
其次,扩缩容比较简单,可以在分钟级别进行扩缩容。由于使用 CubeFS 分布式存储,计算存储分离,所以扩容以后不需要进行数据重分布,扩容后可以直接使用。
另外,ByConity 的云原生部署,运维相对简单。
· CubeFS 的组件相对成熟稳定,扩缩容,灾备方案成熟,出现问题可快速解决;
· 业务高峰期时,可以通过快速扩容资源保障 SLA;
· 业务低峰期时,可以通过缩减存储/计算资源达到降低成本的目的;
· CubeFS 高达 5GB/s-8GB/s 每秒的 写-读 速度, 使 ByConity 的查询速度更快。
在 MetaApp 是如何使用 CubeFS 的
1、使用 docker 在 14 台机器上进行部署:
· 三节点部署 Master、Clustermgr、MetaNode、Consul
配置为:40 核心、256G 内存、 一块 1T SATA SSD、10Gbps 网络
· 10 节点部署 Access、BlobNode
配置为:96 核心、256G 内存、5 块 7.6TNvme、10 块 3.68T SATA SSD(两块聚合为一个 7T 的磁盘)、20Gbps 网络(10Gbps 两个网口聚合)
· 1 节点部署 Proxy、Scheduler、ObjectNode
配置为:40 核心、256G 内存,8T HDD,10Gbps 网络
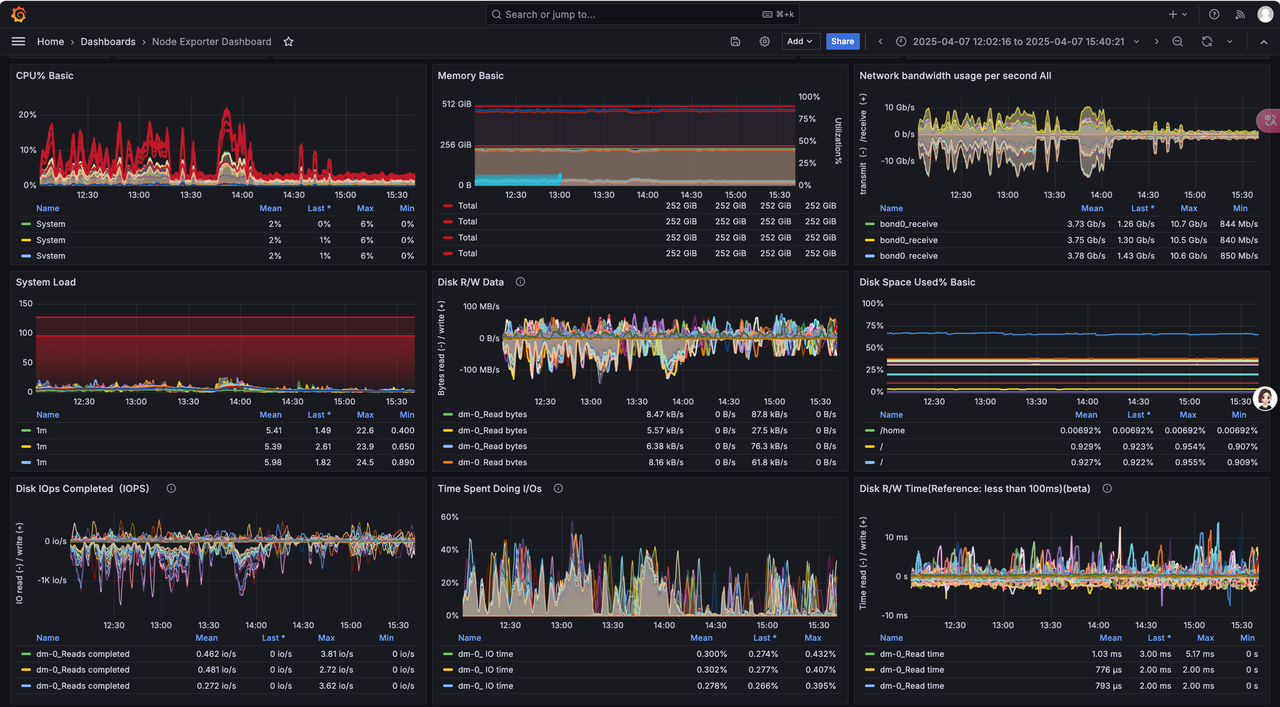
2、参照官方提供的文档 集成 prometheus 与 Grafana
· 一个节点部署 prometheus 与 Grafana
· cubefs 集群监控
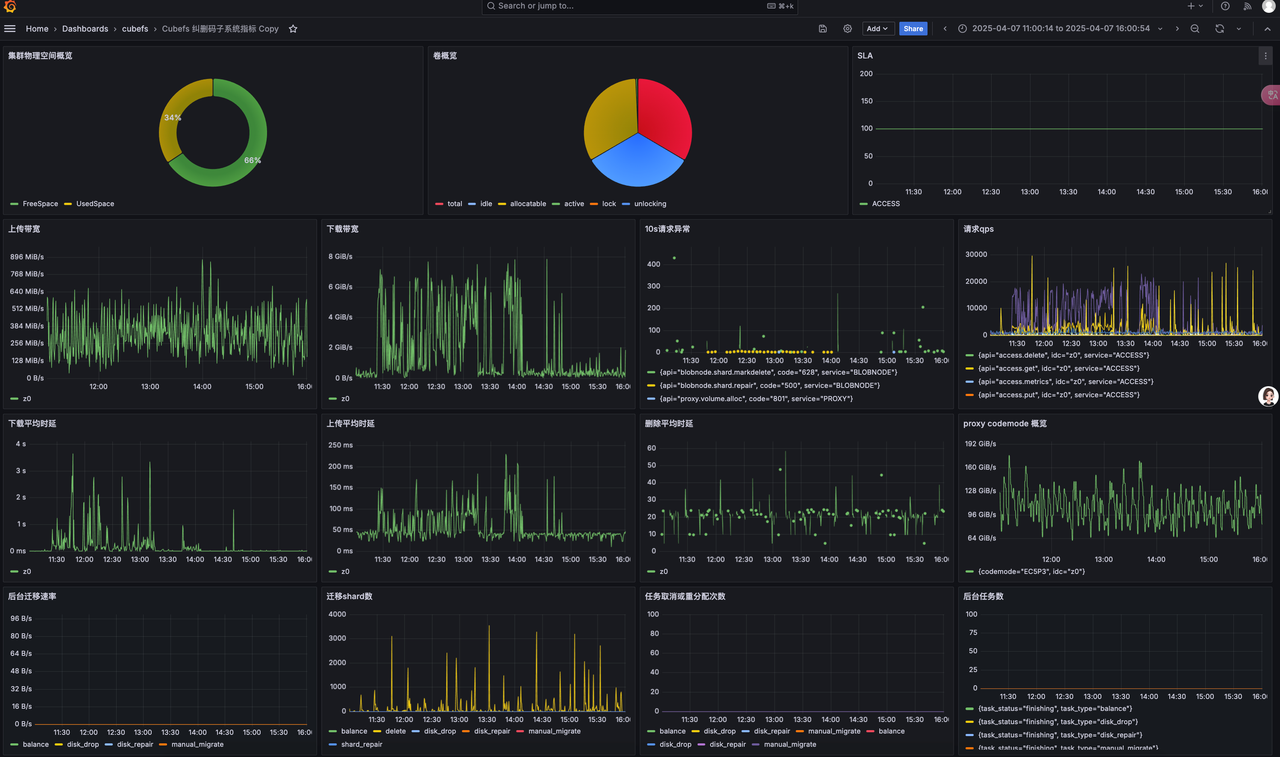
· Cubefs Master、Clustermgr、MetaNode、Consul 节点监控
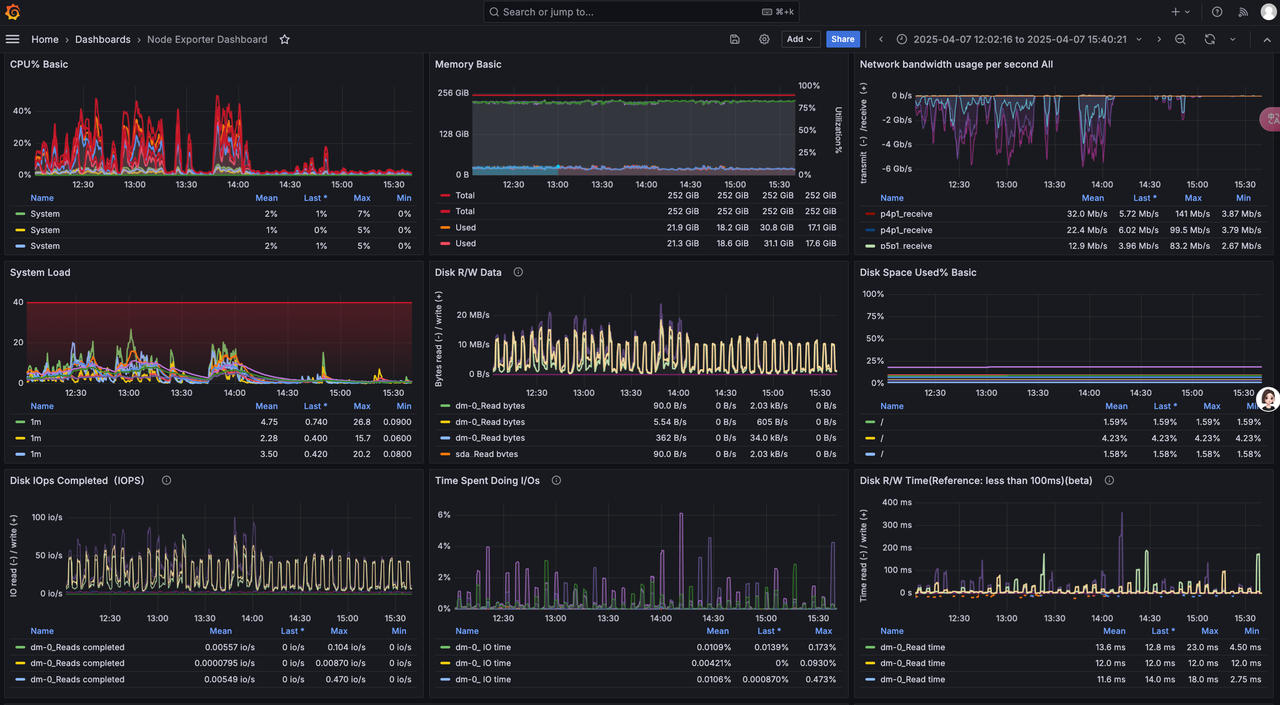
· Cubefs Access、BlobNode 节点监控
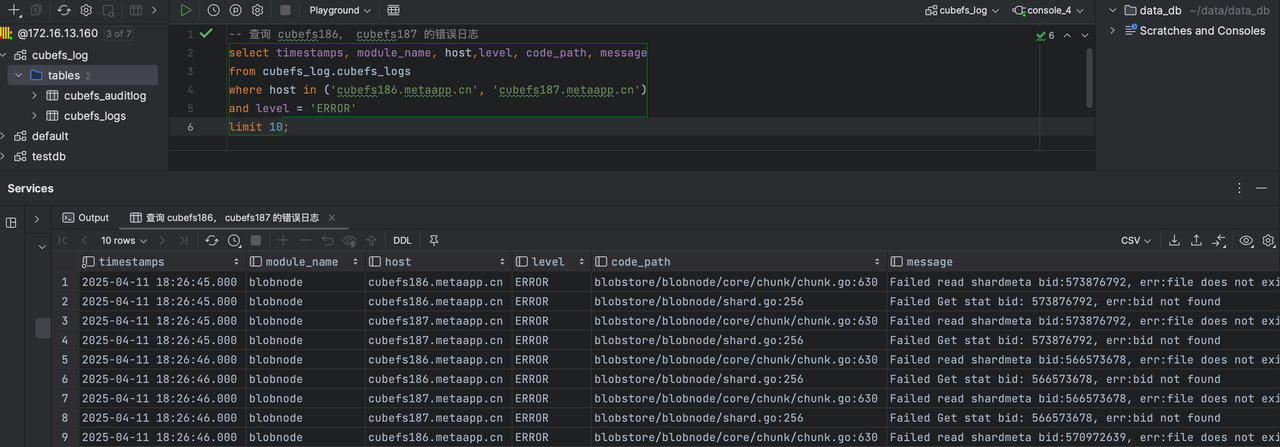
3、使用 vector 来收集日志,clickhouse 存储查询日志。
· Clickhouse 建表语句
-- 用于存放 cubefs 的日志
CREATE TABLE cubefs_log.cubefs_logs
(
`_timestamp` Int64,
`timestamps` DateTime64(3) MATERIALIZED toDateTime64(_timestamp / 1000000, 6),
`ck_date` Date MATERIALIZED toDate(timestamps),
`module_name` String,
`host` Nullable(String),
`level` Nullable(String),
`code_path` Nullable(String),
`trace_span` Nullable(String),
`message` Nullable(String)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ck_date)
ORDER BY _timestamp
TTL ck_date + toIntervalDay(16)
SETTINGS index_granularity = 8192
-- 用于存放 cubefs 的审计日志
CREATE TABLE cubefs_log.cubefs_auditlog
(
`_timestamp` Int64,
`timestamps` DateTime64(3) MATERIALIZED toDateTime64(_timestamp / 1000000, 6),
`ck_date` Date MATERIALIZED toDate(timestamps),
`module_name` String,
`host` Nullable(String),
`req` Nullable(String),
`server_name` Nullable(String),
`req_type` Nullable(String),
`req_api` Nullable(String),
`req_headers` Nullable(String),
`req_body` Nullable(String),
`response_code` Nullable(String),
`response_headers` Nullable(String),
`response_body` Nullable(String),
`response_length` Nullable(Int64),
`response_time_us` Nullable(Int64)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ck_date)
ORDER BY _timestamp
TTL ck_date + toIntervalDay(16)
SETTINGS index_granularity = 8192
· vector 收集日志 vector.toml 配置
需要大家自行安装 vector, 根据自身情况修改下面的 vector.toml 配置中的 日志地址 和 clickhouse 的配置地址
# Set global options
data_dir = "/var/lib/vector"
# Vector's API (disabled by default)
# Enable and try it out with the command
[api]
enabled = false
# address = "127.0.0.1:8686"
[sources.cubefs_cfs_logs]
type = "file"
include = ["/ssd1/cubefs/metanode/logs/metaNode/metaNode_*.log","/ssd1/cubefs/master/logs/master/master_*.log", "/ssd1/cubefs/clustermgr/logs/*.log"] # 这里配置为你自己的 cubefs 的日志地址
ignore_older_secs = 604800
[transforms.cubefs_cfs_log_parser]
inputs = ["cubefs_cfs_logs"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[3]
. |= parse_regex!(.message, r'^(?P<log_timestamp>\d+/\d+/\d+ \d+:\d+:\d+\.\d+) \[(?P<level>\w+)[\s]?\] (?P<code_path>\S+) (?P<trace_span>\[[^:]+:[^:]+\] )?(?P<message>.*)$')
.timestamp = parse_timestamp(.log_timestamp, "%Y/%m/%d %H:%M:%S.%f") ?? now()
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.file_parts)
del(.log_timestamp)
'''
# Ingest data by tailing one or more files
[sources.cubefs_blob_logs]
type = "file"
include = ["/var/log/cubefs/*/*.log", ] ## 这里配置为你自己的 cubefs 的日志地址
ignore_older_secs = 604800
# Structure and parse via Vector's Remap Language
[transforms.cubefs_blob_log_parser]
inputs = ["cubefs_blob_logs"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[4]
. |= parse_regex!(.message, r'^(?P<log_timestamp>\d+/\d+/\d+ \d+:\d+:\d+\.\d+) \[(?P<level>\w+)\] (?P<code_path>\S+) (?P<trace_span>\[[^:]+:[^:]+\] )?(?P<message>.*)$')
.timestamp = parse_timestamp(.log_timestamp, "%Y/%m/%d %H:%M:%S.%f") ?? now()
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.file_parts)
del(.log_timestamp)
'''
[sinks.ck_cubefs_logs]
type = "clickhouse"
inputs = ["cubefs_blob_log_parser", "cubefs_cfs_log_parser"]
compression = "gzip"
database = "cubefs_log"
endpoint = "http://172.16.13.160:8123" # 这里刚换为你自己的 Clickhouse 地址
format = "json_each_row"
table = "cubefs_logs"
skip_unknown_fields = true
auth.strategy = "basic"
auth.user = "default"
auth.password = "xxxxx" # 这里刚换为你自己的 Clickhouse 密码
batch.max_bytes = 20971520
batch.timeout_secs = 10
buffer.max_events = 10000
###### cubefs auditlog
# Ingest data by tailing one or more files
[sources.cubefs_blob_auditlog]
type = "file"
include = ["/var/log/cubefs/*/auditlog/*.log"] // 这里配置为你自己的 cubefs 的日志地址
ignore_older_secs = 604800
# Structure and parse via Vector's Remap Language
[transforms.cubefs_blob_auditlog_parser]
inputs = ["cubefs_blob_auditlog"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[4]
split_message = split!(.message, "\t")
.req = split_message[0]
.server_name = split_message[1]
.log_timestamp = split_message[2]
.req_type = split_message[3]
.req_api = split_message[4]
.req_headers = split_message[5]
.req_body = split_message[6]
.response_code = split_message[7]
.response_headers = split_message[8]
.response_body = split_message[9]
.response_length = split_message[10]
.response_time_us = split_message[11]
.log_timestamp = to_int(.log_timestamp)*100 ?? 0
.timestamp = from_unix_timestamp!(.log_timestamp, unit: "nanoseconds")
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.timestamp)
del(.log_timestamp)
'''
[sinks.ck_cubefs_auditlog]
type = "clickhouse"
inputs = ["cubefs_blob_auditlog_parser"]
compression = "gzip"
database = "cubefs_log"
endpoint = "http://172.16.13.160:8123" # 这里刚换为你自己的 Clickhouse 地址
format = "json_each_row"
table = "cubefs_auditlog"
skip_unknown_fields = true
auth.strategy = "basic"
auth.user = "default"
auth.password = "xxxx" # 这里刚换为你自己的 Clickhouse 密码
batch.max_bytes = 20971520
batch.timeout_secs = 10
buffer.max_events = 10000
· 我们目前直接使用 SQL 查询日志,如果大家有精力也可以尝试 clickvisual 来做日志分析查询。
查询日志
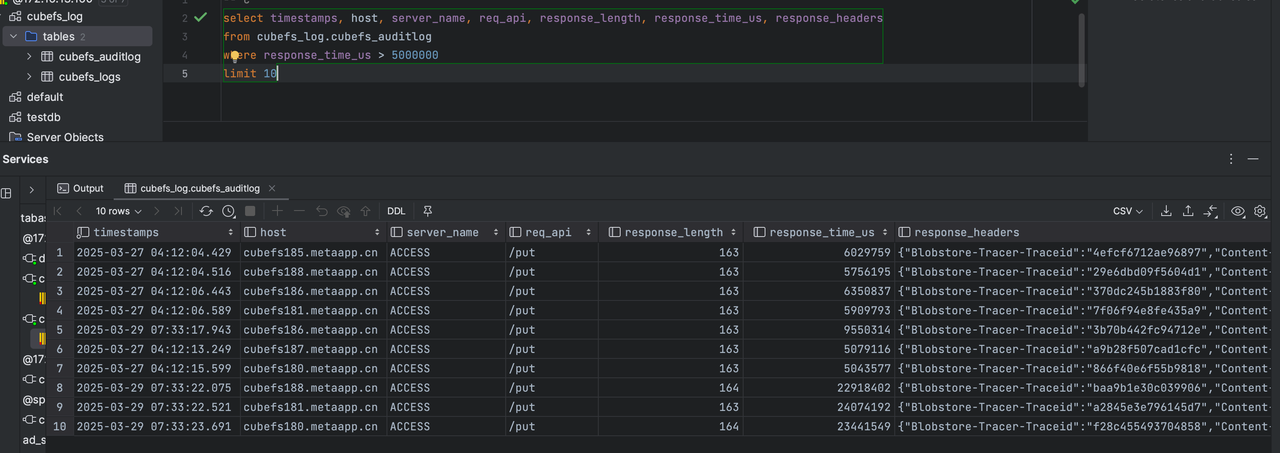
查询审计日志
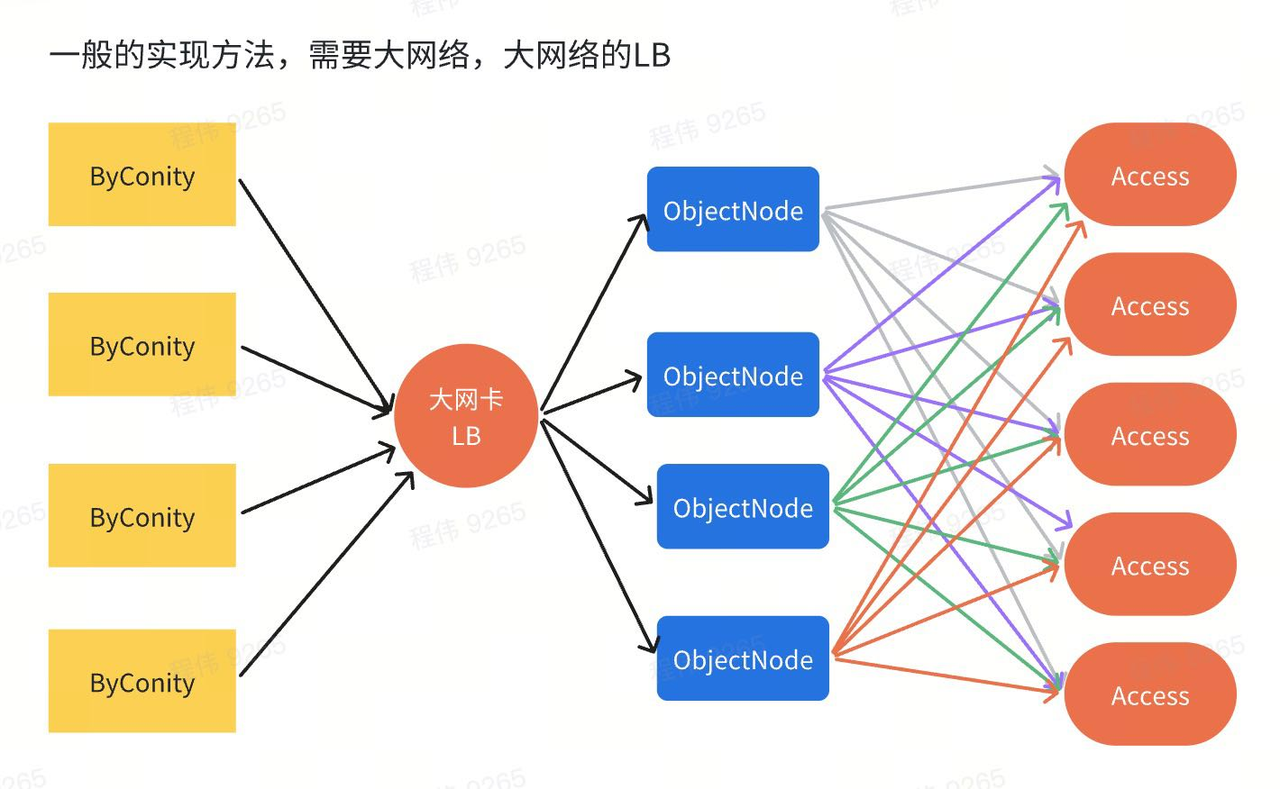
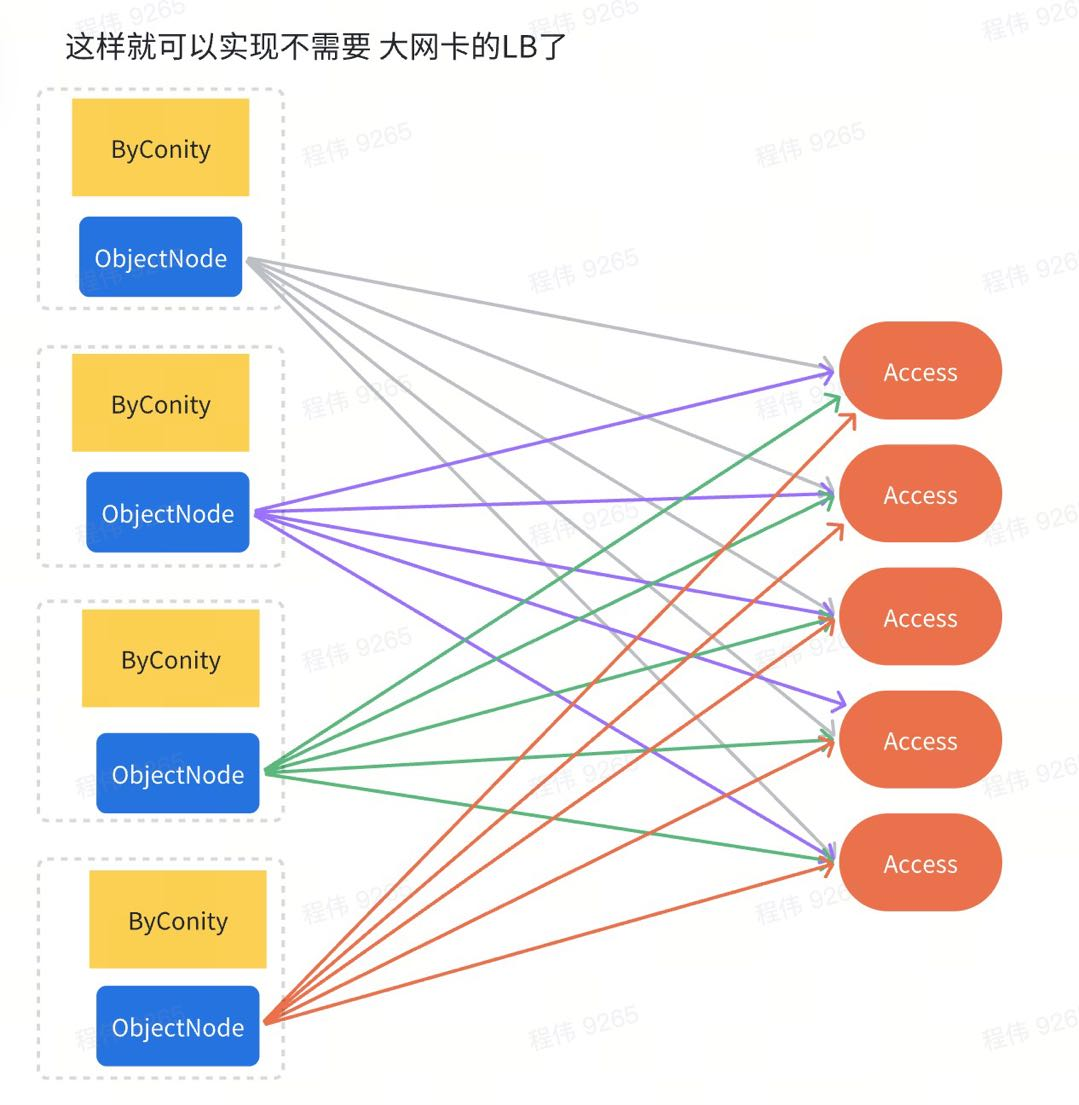
4、在 ByConity 的部署节点上部署 ObjectNode,降低 LB 负载均衡的压力,无需 100Gbps/s 的网卡,就可以通过节点带宽聚合实现 80Gbps 的网络效果。
遇到的问题与解决方式
CubeFS Object Node 服务部署:cubefs 通过 objectNode 实现 S3 接口,由于 cubefs 需要大量的读带宽高达 64Gbps,而我们没有这么大的 LB 机器,所以只能将 objectNode 部署到 ByConiy 所在的机器上,通过直接负载访问 Access,实现了 8 节点 64Gbps 带宽的访问效果
CubeFS S3 场景空目录优化:CubeFS 由于使用了在创建对象文件时,会将文件前缀转换成目录,而 ByConity 在使用时会创建大量带有前缀的对象,删除对象后,不删除目录,导致空目录大量占据元数据的存储空间,通过在 ObjectNode 的删除接口中添加递归删除空目录的代码解决这个问题。(由于这个问题只存在 S3 场景,所以只修改 ObjectNode 的 S3 接口)
CubeFS 纠删码 策略调整:由于我们只有 10 个存储节点,使用 6+3 的部署模式的话,只要两个节点挂掉就会导致无法创建新的卷,所以我们调整为 5+3,这样挂掉两个节点后,依然可以正常读写数据。
BlobNode 节点内核调整:由于 BlobNode 节点使用 centos7 系统, 内核版本 3.10.0 太低,导致 导致 nvem 的平均 IO 延迟太高(30 多 ms), 升级内核到 6.6.12 后,平均 IO 延迟降低到了 4ms。
多交换机之间的带宽限制: 由于 数据存储节点与数据读写节点在不同交换机下, 我们发现下载速度卡在 40Gbps, 通过排除发现交换机之间的带宽被打满了(万兆网络通畅为 40gbps),我们通过把数据读节点与数据存储节点的网线插到一个交换机上, 就可以充分打满网卡. 而写场景的需求并不大,就可以部署在其他交换机上.
未来展望:
· 尝试 CubeFS 的分层模式,在性能和性价比之间找到一个平衡点。
· 尝试 CubeFS 的 ACCESS 通过 SDK 的方式与 ObjectNode 集成在一起的模式,降低延迟,在有限的硬件基础上提供更高的带宽。