
ByConity x CubeFS: A cloud-native build solution for trillion-scale OLAP platforms
Open source components involved
CubeFS | https://github.com/cubefs/cubefs |
CubeFS is a new generation of cloud native storage product. It is currently a graduate open source project hosted by Cloud Native Computing Foundation (CNCF). It is compatible with multiple access protocols such as S3, POSIX, HDFS, and supports two storage engines, multi-copy and erasure code. It is widely used in big data, AI, container platform, database, middleware storage and computing separation, data sharing, data protection and other scenarios. It is now maintained by OPPO.
ByConity| https://github.com/ByConity/ByConity |
ByConity is an open source distributed cloud-native SQL data warehouse engine based on ClickHouse kernel. It is good at interactive query and AD hoc query. It supports complex query of multi-table association, no sense of cluster expansion, and unified summary of offline batch data and real-time data stream. Open source and maintained by Byte.
About MetaApp
MetaApp is a leading game developer and operator in China. It focuses on the efficient distribution of mobile information and is committed to building a virtual world for all ages. By 2023, MetaApp has more than 200 million registered users, and Intertransport has collaborated on 200,000 games, with a cumulative distribution of more than 1 billion. It has 233 parks, 233 parties and other applications
About Pandora
With the growth of business and the proposal of refined operation, the product puts forward higher requirements for the data department, including the need to query and analyze real-time data and quickly adjust the operation strategy. AB experiments were performed on a small number of people to verify the effectiveness of the new function. Reduce the data query time, reduce the difficulty of data query, so that non-professionals can analyze and probe data independently.
In order to meet the business requirements, we have implemented an OLAP data analysis platform based on Clickhouse, which integrates event analysis, conversion analysis, custom retention, user grouping and marking, behavior flow analysis, and AB experiment.
Introduction to Platform Functions
· Event analysis: The collected user events can be filtered, grouped, and summarized flexibly. Filter according to the buried point data, do some grouping of user attributes or filter of global attributes, and display the data after the query is completed, which can be displayed by column and day.
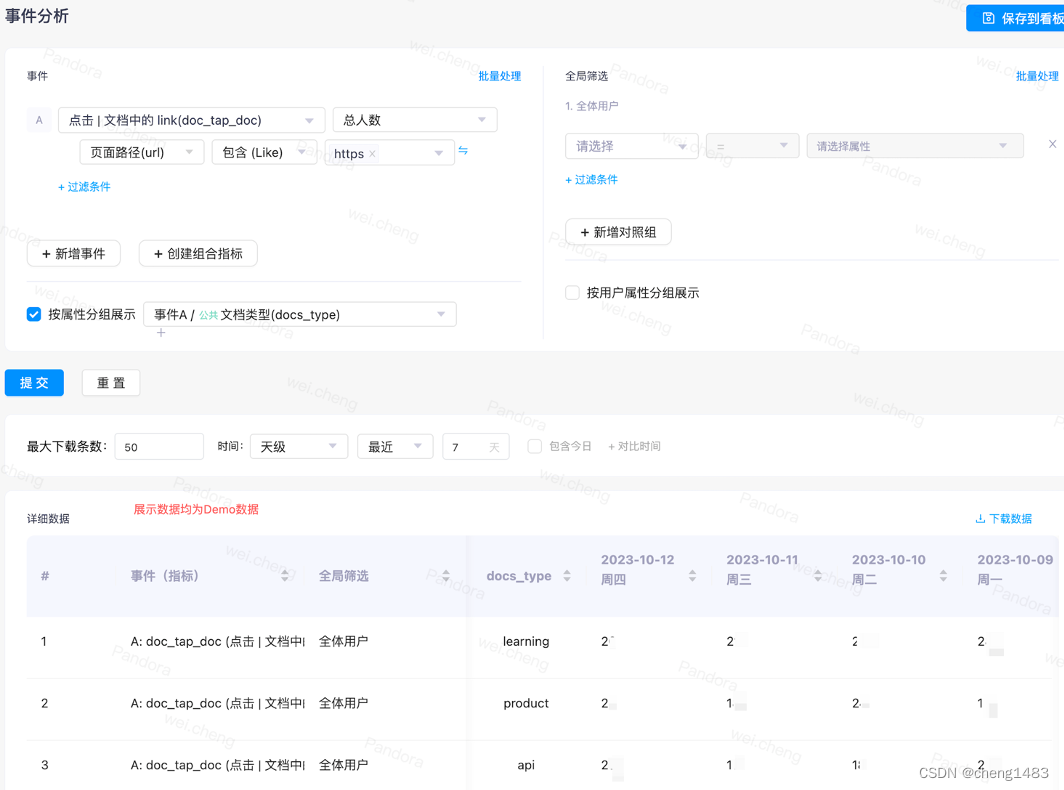
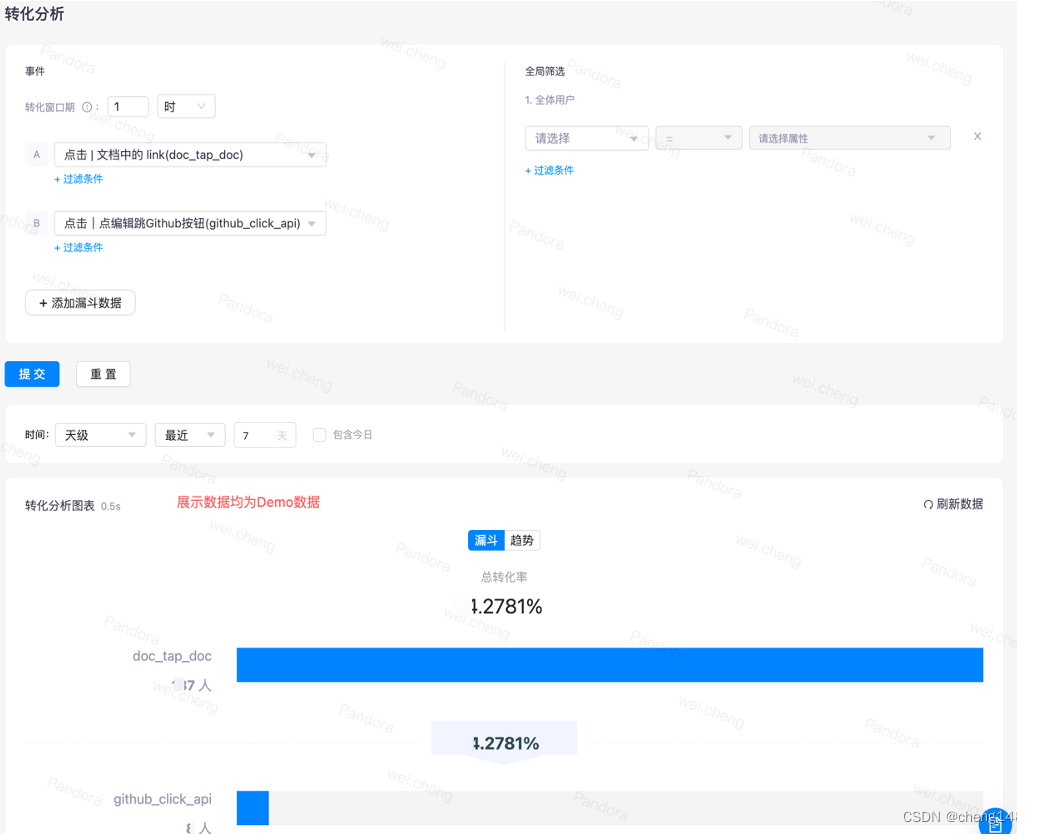
· Conversion analysis: analyze the conversion of users to the product, namely funnel analysis. Based on the start event and end event selected, query the transformation in a specific time.
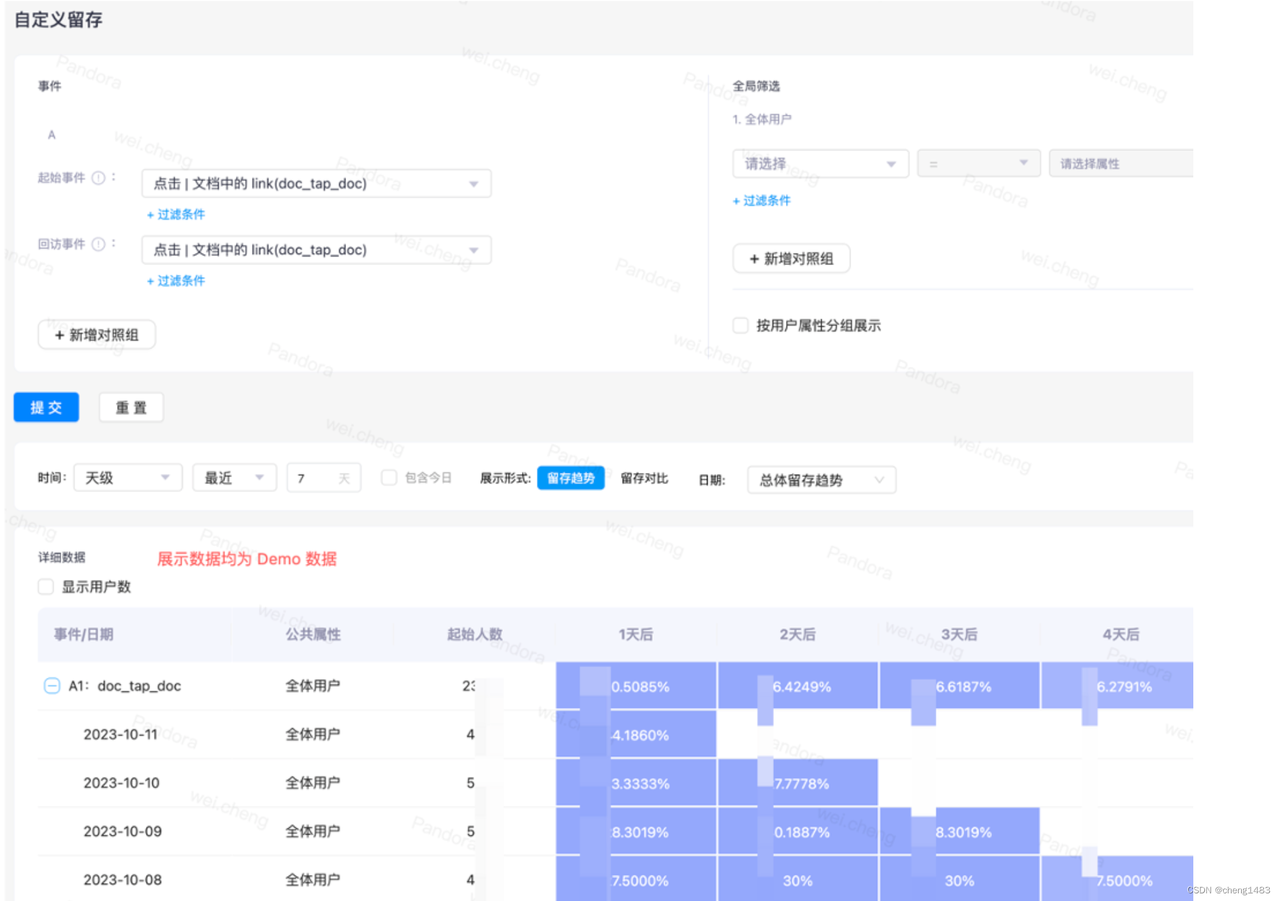
· Retention analysis: Analyzing how long a user comes back to the product after using it. The ladder diagram is generated according to the starting event and the return visit event.
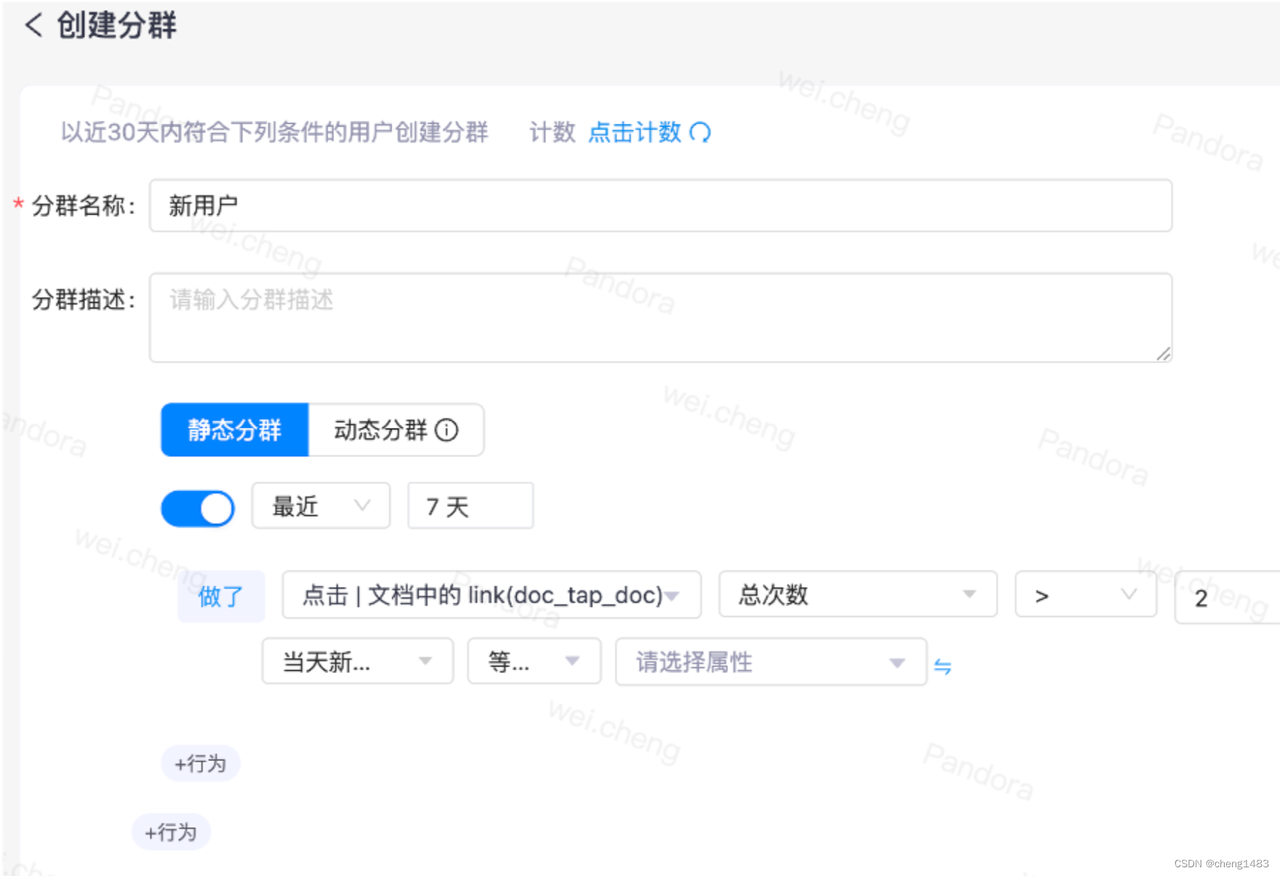
· User segmentation: This is used to filter and analyze the data for a specific user group. According to the conditions, the eligible users are filtered out and grouped, and the corresponding indicators are queried according to the clustering results, such as stay time, play time, etc., to provide assistance for the business.
· Behavior stream: Used to analyze a single behavior stream of a single user. It's mostly used to see specific events for certain users, such as whether they watched an AD in its entirety.
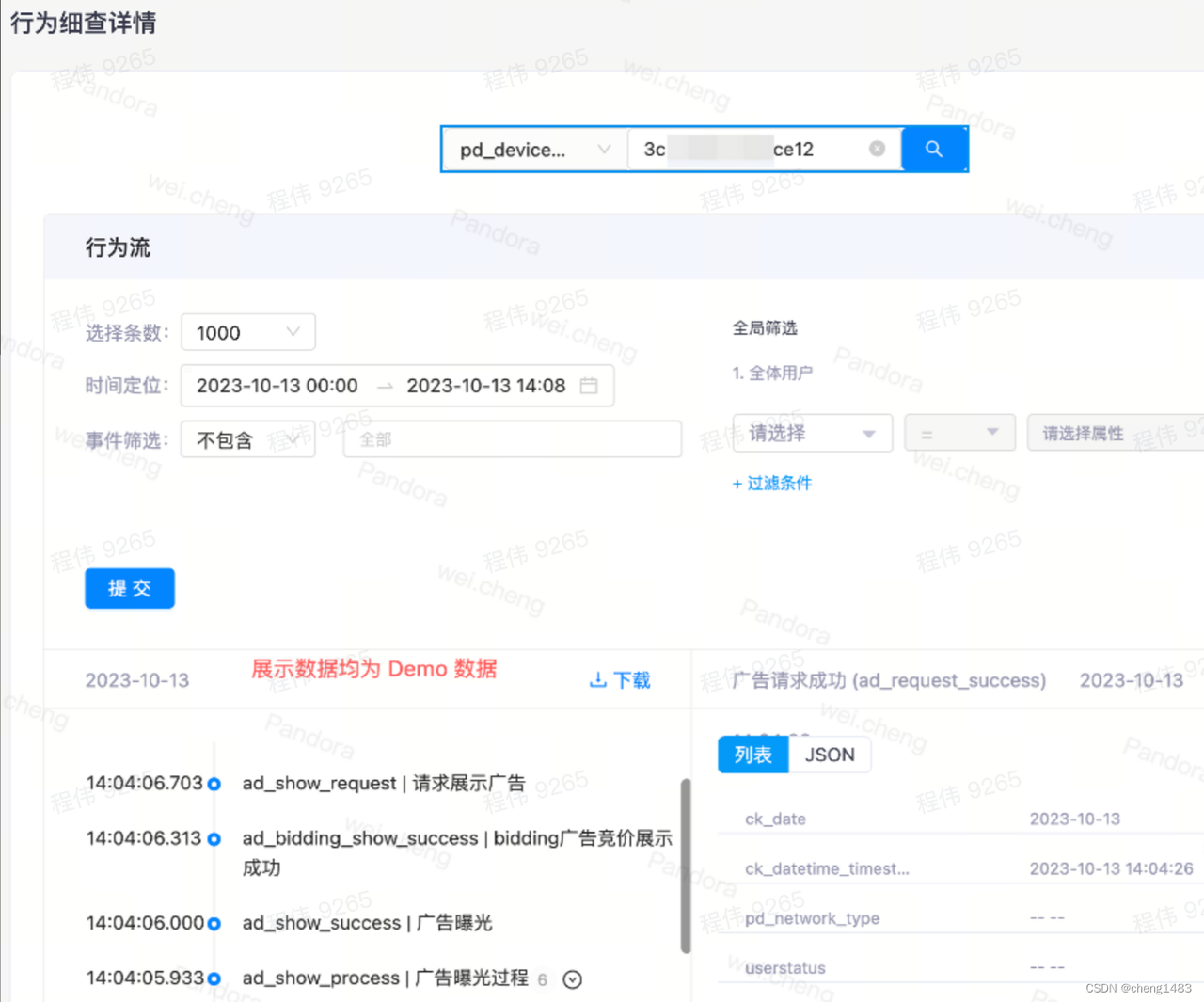
· AB experiment: Take a small portion of the traffic from the line and test the new feature
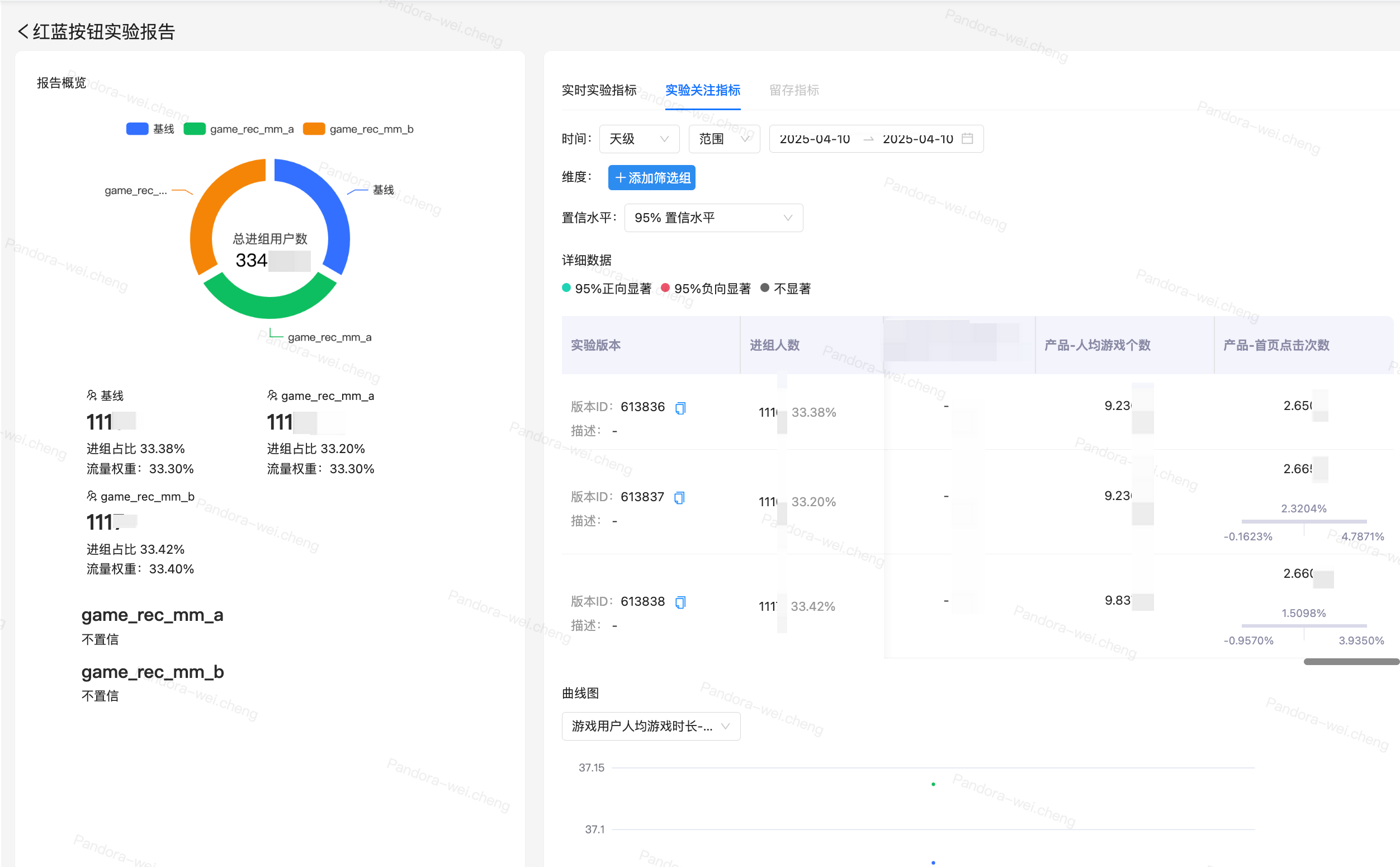
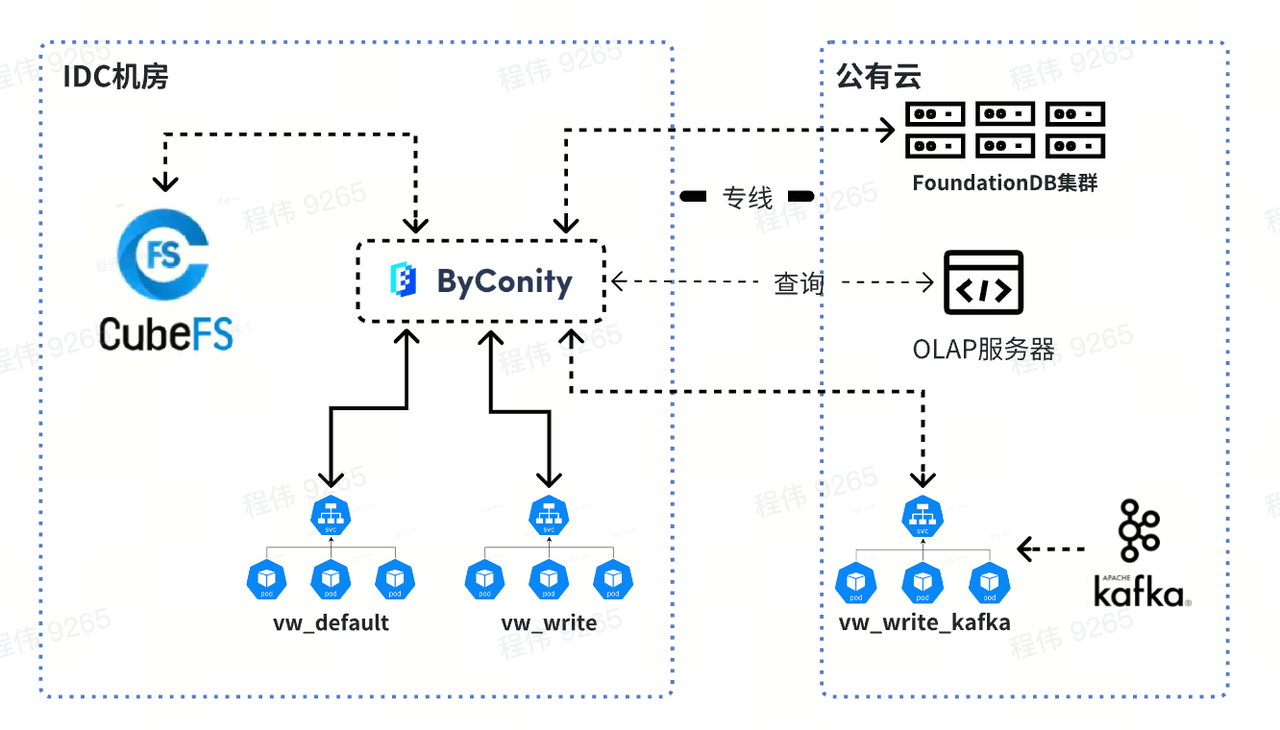
Platform data flow diagram
This is a typical OLAP architecture with two parts, one offline and one real-time.
In the offline scenario, we used DataX to integrate Kafka data into Hive data bins and regenerate BI reports. BI reports use Pandora's BI reporting capabilities to display results.
In the real-time scenario, one line uses GoSink for data integration and integrates GoSink data into ClickHouse, and the other line uses CnchKafka to integrate data into ByConity. Finally, the data was obtained through the OLAP query platform for query.
Problem encountered
Data Volume and Business Situation:

At our peak, our application buried 1,500 + burial points, generating 40 + billion logs a day and taking up 100+ terabytes of uncompressed storage.
Due to the tidal business, holiday business volume explosive growth, weekday business volume is calm without waves.
We store all the buried points in a Clickhouse wide table with nearly 3000+ columns.
Clickhouse quickly showed problems as usage grew:
Problem 1: Read-write integration is easy to preempt resources and cannot guarantee read/write stability
During peak traffic, writes can cause a lot of I/O and CPU overhead, resulting in queries that take longer. The same is true for data queries;
Problem 2: expansion/contraction capacity trouble, long cycle
· Long expansion/shrinkage time: Since the machine is in IDC and belongs to the private cloud, one of the problems is that the node increase cycle is particularly long. It takes a week to two weeks from increasing the demand of nodes to really increasing good nodes, which affects the business.
· Unable to expand or shrink quickly: after expansion or shrink, the data distribution should be re-carried out, otherwise the node pressure is very large;
Problem 3: the operation and maintenance is cumbersome, and the SLA cannot be guaranteed during the peak period of business
· Data query is often slow and data writing is delayed (gradually from several hours to several days) due to business node failure;
· There is a serious shortage of resources in the peak period of business, and it is impossible to expand resources in the short term. Only by deleting the data of part of the business, it can provide services for the business with high priority;
· During the low peak period of business, a lot of resources are idle and the cost is inflated. Although we are in IDC, but IDC machine purchase is also subject to cost control, and can not unlimited node expansion, in addition, there is a certain cost consumption in normal use;
· Unable to interact with cloud resources;
Solution
Why select ByConity
Because ByConity is built on top of the Clickhouse kernel and compatible with Clickhouse SQL, ByConity is the least expensive test, Byconity has been production-tested by bytes, and you don't have to worry about it.
About ByConity:
ByConity is an open source cloud-native data warehouse based on ClickHouse. Both have the following characteristics:
· Very fast writing speed, suitable for writing a large amount of data, the amount of data written can reach 50MB-200MB /s
· Very fast query speed, in the case of massive data, the query speed can reach 2-30GB/s
· High data compression ratio, low storage cost, compression ratio can reach 0.2 ~ 0.3
ByConity has the advantages of ClickHouse, maintains good compatibility with ClickHouse, and enhances read/write separation, elastic scaling, and strong data consistency. Both are suitable for the following OLAP scenarios:
· Datasets can be large - billions or trillions of rows
· A data table contains many columns
· Query only specific columns
· Results must be returned in milliseconds or seconds
In the previous sharing, ByConity community has compared the two from the perspective of usage, and summarized them as follows:
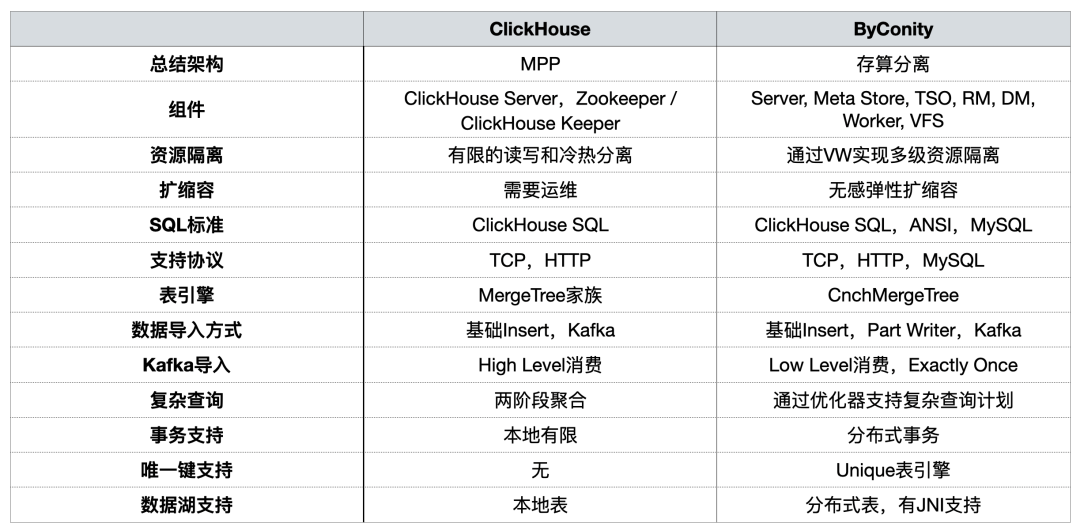
During the construction of OLAP platform, we focused on resource isolation, scaling, complex query, and distributed transaction support.
Why Select CubeFS
We chose ByConity as the component to replace Clickhouse, but since ByConity is a cloud-native architecture with separation of storage and computing, we need to store data into HDFS/S3, so choosing an S3 store was our primary goal. After investigating minio, seaweedfs and juicefs, CubeFS is finally selected. CubeFS is widely used in the production of large factories such as OPPO and Jingdong, and its stability and maturity are higher.
About CubeFS:
CubeFS (formerly known as ChubaoFS) is a new generation cloud-native open source storage system, which is a graduation project of Cloud Native Computing Foundation (CNCF). The open source project is maintained and developed by the community and OPPO and other companies, and continues to optimize and evolve in the fields of cloud storage and high performance computing.
CubeFS supports access protocols such as S3, HDFS and POSIX, and is widely applicable to scenarios such as big data, AI/LLMs, container platforms, databases and middleware, providing capabilities such as storage and computing separation, data sharing and distribution. It can be expanded quickly and on demand.
CubeFS consists of Metadata Subsystem, Data Subsystem, resource management node Master and Object Subsystem. The stored data can be accessed through the POSIX/HDFS/S3 interface.
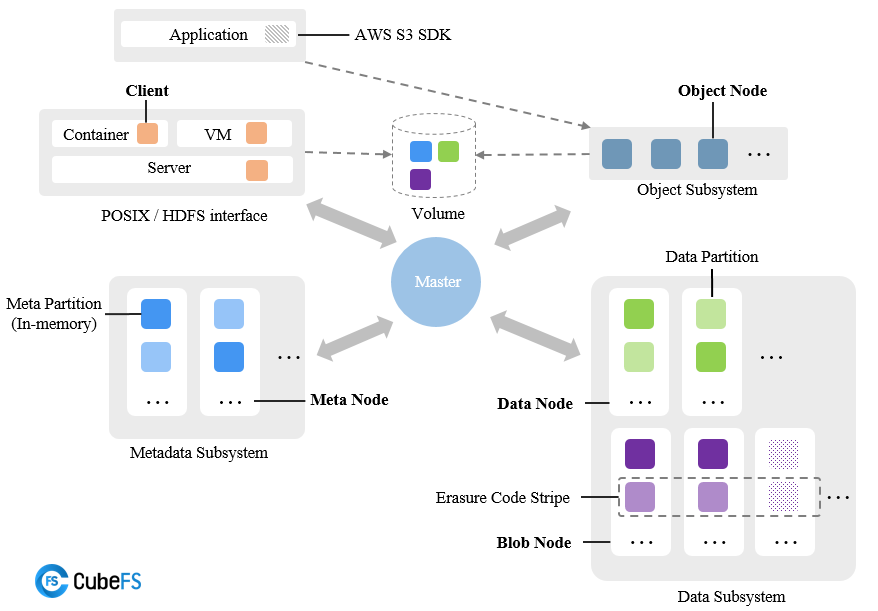
Final component diagram
What problems were solved
Firstly, ByConity read-write separation can ensure the stability of read-write tasks by isolating computing resources. If there are not enough tasks to read, the corresponding resources can be extended to make up for what is not enough, including using resources on the cloud for expansion.
Second, scaling is relatively simple and can be done at the level of minutes. Due to the use of CubeFS distributed storage, computing and storage are separated, so no data redistribution is needed after the expansion, and it can be used directly after the expansion.
In addition, ByConity's cloud-native deployment is relatively simple to operate and maintain.
· The components of CubeFS are relatively mature and stable, and the disaster recovery scheme is mature, so the problems can be solved quickly;
· During peak service hours, SLA can be guaranteed by rapidly expanding capacity resources;
· During the low peak period, the cost can be reduced by reducing storage/computing resources;
· CubeFS has a write-read speed of up to 5GB/ s-8Gb /s per second, making ByConity's queries faster.
How is CubeFS used in MetaApp
- Deploy on 14 machines using docker:
· Three nodes deploy Master, Clustermgr, MetaNode and Consul
The configuration is: 40 cores, 256G memory, one 1T SATA SSD, 10Gbps network
· 10 Nodes deploy Access and BlobNode
Configuration: 96 cores, 256G RAM, 5 7.6TNvme, 10 3.68T SATA SSDS (two aggregated into a 7T disk), 20Gbps network (10Gbps two network ports aggregated)
· 1 Nodes deploy Proxy, Scheduler, and ObjectNode
Configuration: 40 cores, 256G memory, 8T HDD, 10Gbps network
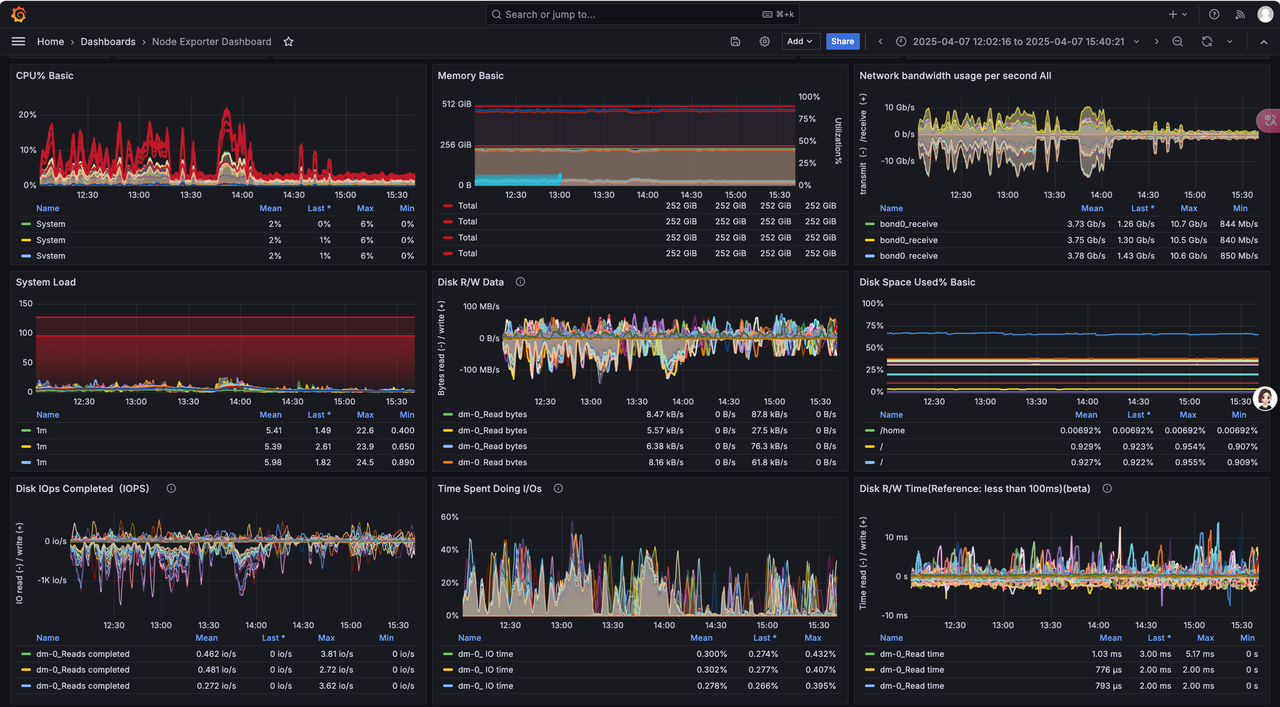
- Integrate prometheus and Grafana according to the official documentation
· prometheus and Grafana deployed on one node
· cubefs cluster monitoring
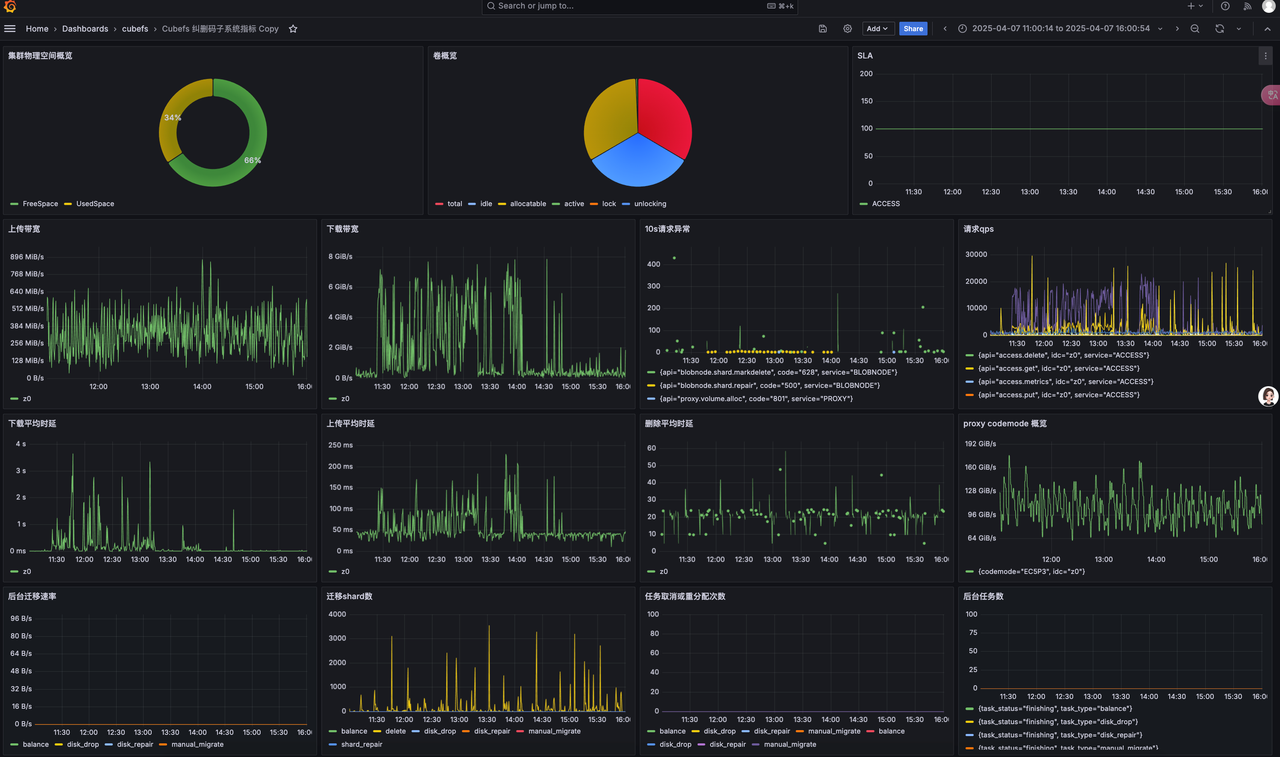
· Cubefs Master、Clustermgr、MetaNode、Consul
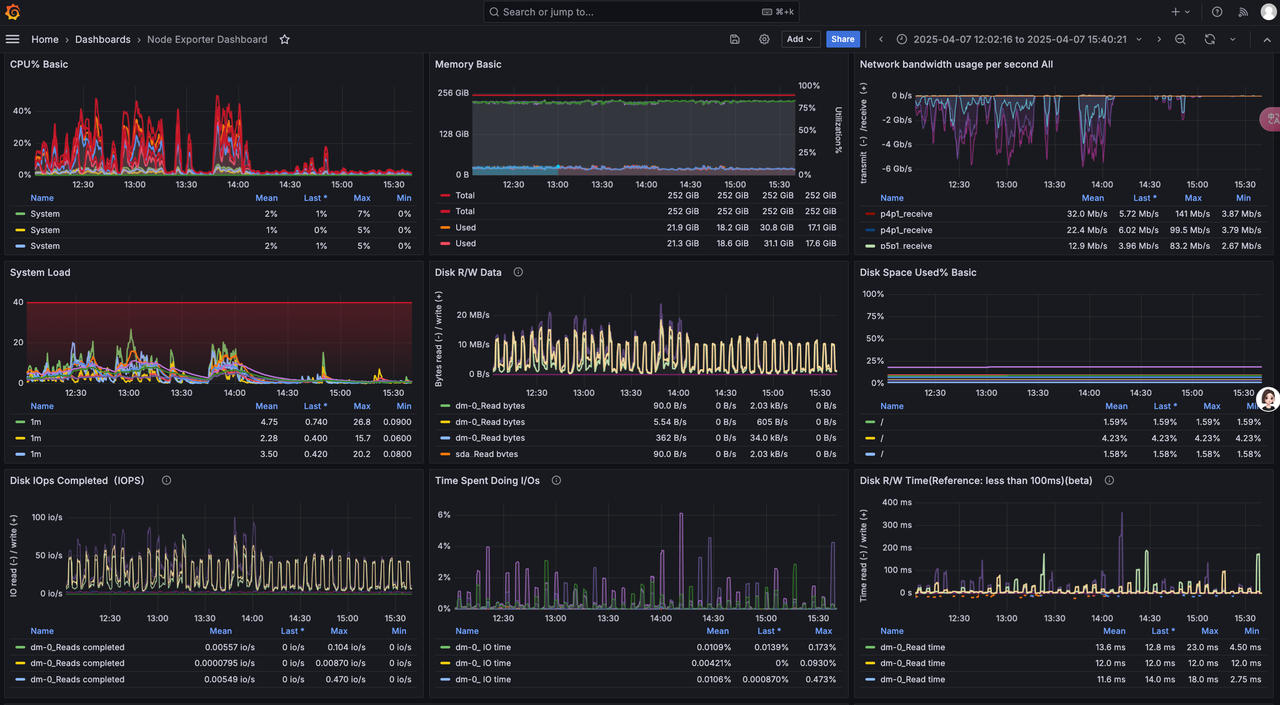
· Cubefs Access、BlobNode
3、Use vector to collect logs and clickhouse to store query logs.
· Clickhouse builds predicates
-- Used to store cubefs logs
CREATE TABLE cubefs_log.cubefs_logs
(
`_timestamp` Int64,
`timestamps` DateTime64(3) MATERIALIZED toDateTime64(_timestamp / 1000000, 6),
`ck_date` Date MATERIALIZED toDate(timestamps),
`module_name` String,
`host` Nullable(String),
`level` Nullable(String),
`code_path` Nullable(String),
`trace_span` Nullable(String),
`message` Nullable(String)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ck_date)
ORDER BY _timestamp
TTL ck_date + toIntervalDay(16)
SETTINGS index_granularity = 8192
-- Used to store cubefs audit logs
CREATE TABLE cubefs_log.cubefs_auditlog
(
`_timestamp` Int64,
`timestamps` DateTime64(3) MATERIALIZED toDateTime64(_timestamp / 1000000, 6),
`ck_date` Date MATERIALIZED toDate(timestamps),
`module_name` String,
`host` Nullable(String),
`req` Nullable(String),
`server_name` Nullable(String),
`req_type` Nullable(String),
`req_api` Nullable(String),
`req_headers` Nullable(String),
`req_body` Nullable(String),
`response_code` Nullable(String),
`response_headers` Nullable(String),
`response_body` Nullable(String),
`response_length` Nullable(Int64),
`response_time_us` Nullable(Int64)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(ck_date)
ORDER BY _timestamp
TTL ck_date + toIntervalDay(16)
SETTINGS index_granularity = 8192
· vector collects log vector.tomL configuration
You need to install vector yourself, and change the log and clickhouse configuration addresses in the vector.toml configuration below to suit your needs.
# Set global options
data_dir = "/var/lib/vector"
# Vector's API (disabled by default)
# Enable and try it out with the command
[api]
enabled = false
# address = "127.0.0.1:8686"
[sources.cubefs_cfs_logs]
type = "file"
include = ["/ssd1/cubefs/metanode/logs/metaNode/metaNode_*.log","/ssd1/cubefs/master/logs/master/master_*.log", "/ssd1/cubefs/clustermgr/logs/*.log"] # 这里配置为你自己的 cubefs 的日志地址
ignore_older_secs = 604800
[transforms.cubefs_cfs_log_parser]
inputs = ["cubefs_cfs_logs"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[3]
. |= parse_regex!(.message, r'^(?P<log_timestamp>\d+/\d+/\d+ \d+:\d+:\d+\.\d+) \[(?P<level>\w+)[\s]?\] (?P<code_path>\S+) (?P<trace_span>\[[^:]+:[^:]+\] )?(?P<message>.*)$')
.timestamp = parse_timestamp(.log_timestamp, "%Y/%m/%d %H:%M:%S.%f") ?? now()
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.file_parts)
del(.log_timestamp)
'''
# Ingest data by tailing one or more files
[sources.cubefs_blob_logs]
type = "file"
include = ["/var/log/cubefs/*/*.log", ]
ignore_older_secs = 604800
# Structure and parse via Vector's Remap Language
[transforms.cubefs_blob_log_parser]
inputs = ["cubefs_blob_logs"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[4]
. |= parse_regex!(.message, r'^(?P<log_timestamp>\d+/\d+/\d+ \d+:\d+:\d+\.\d+) \[(?P<level>\w+)\] (?P<code_path>\S+) (?P<trace_span>\[[^:]+:[^:]+\] )?(?P<message>.*)$')
.timestamp = parse_timestamp(.log_timestamp, "%Y/%m/%d %H:%M:%S.%f") ?? now()
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.file_parts)
del(.log_timestamp)
'''
[sinks.ck_cubefs_logs]
type = "clickhouse"
inputs = ["cubefs_blob_log_parser", "cubefs_cfs_log_parser"]
compression = "gzip"
database = "cubefs_log"
endpoint = "http://172.16.13.160:8123"
format = "json_each_row"
table = "cubefs_logs"
skip_unknown_fields = true
auth.strategy = "basic"
auth.user = "default"
auth.password = "xxxxx"
batch.max_bytes = 20971520
batch.timeout_secs = 10
buffer.max_events = 10000
###### cubefs auditlog
# Ingest data by tailing one or more files
[sources.cubefs_blob_auditlog]
type = "file"
include = ["/var/log/cubefs/*/auditlog/*.log"]
ignore_older_secs = 604800
# Structure and parse via Vector's Remap Language
[transforms.cubefs_blob_auditlog_parser]
inputs = ["cubefs_blob_auditlog"]
type = "remap"
timezone = "local"
source = '''
.file_parts = split!(.file, "/")
.module_name = .file_parts[4]
split_message = split!(.message, "\t")
.req = split_message[0]
.server_name = split_message[1]
.log_timestamp = split_message[2]
.req_type = split_message[3]
.req_api = split_message[4]
.req_headers = split_message[5]
.req_body = split_message[6]
.response_code = split_message[7]
.response_headers = split_message[8]
.response_body = split_message[9]
.response_length = split_message[10]
.response_time_us = split_message[11]
.log_timestamp = to_int(.log_timestamp)*100 ?? 0
.timestamp = from_unix_timestamp!(.log_timestamp, unit: "nanoseconds")
._timestamp = to_unix_timestamp(.timestamp, unit: "microseconds")
del(.timestamp)
del(.log_timestamp)
'''
[sinks.ck_cubefs_auditlog]
type = "clickhouse"
inputs = ["cubefs_blob_auditlog_parser"]
compression = "gzip"
database = "cubefs_log"
endpoint = "http://172.16.13.160:8123"
format = "json_each_row"
table = "cubefs_auditlog"
skip_unknown_fields = true
auth.strategy = "basic"
auth.user = "default"
auth.password = "xxxx"
batch.max_bytes = 20971520
batch.timeout_secs = 10
buffer.max_events = 10000
· We are currently using SQL to query logs directly, but if you have the energy you can also try clickvisual for log analysis queries.
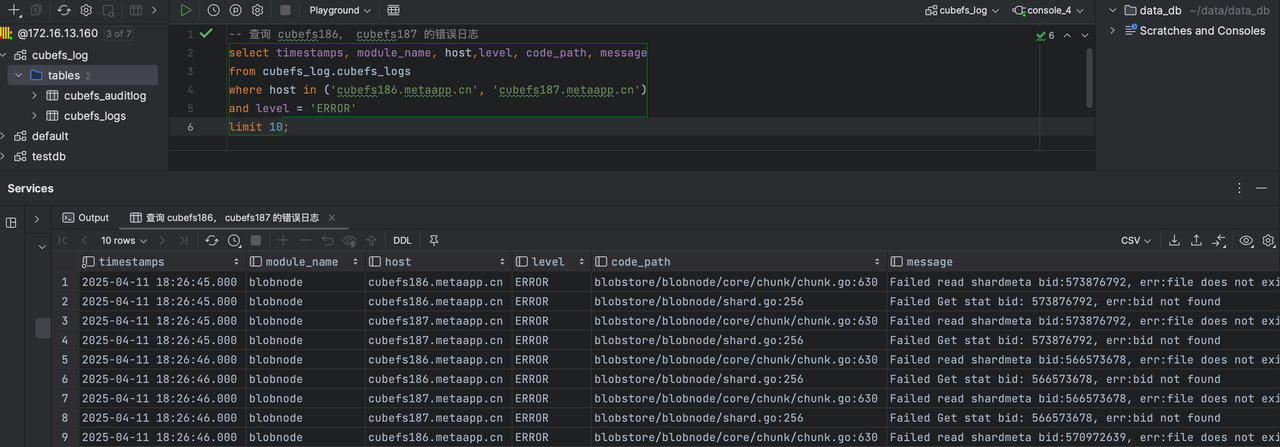
Query log
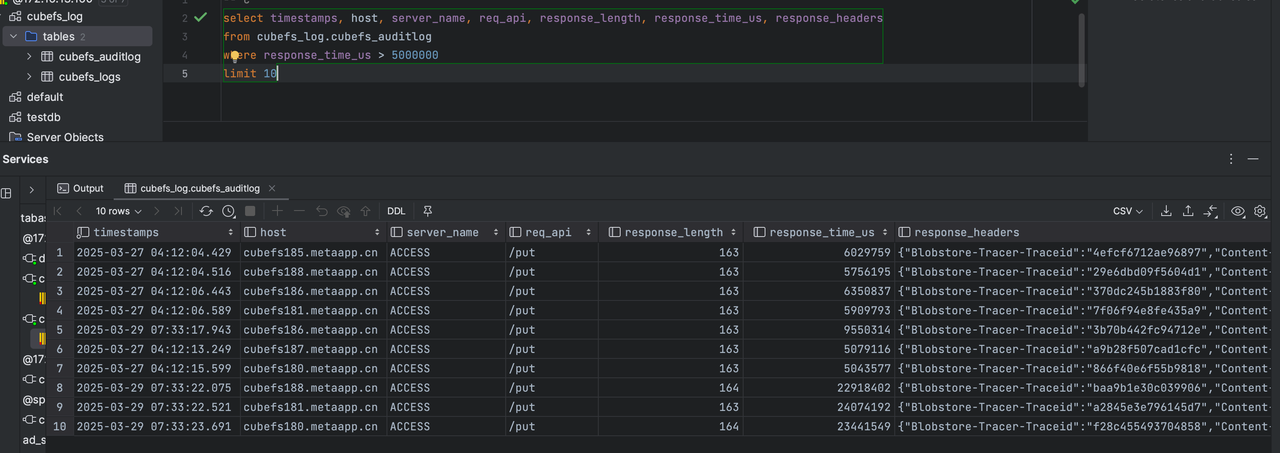
Query audit logs
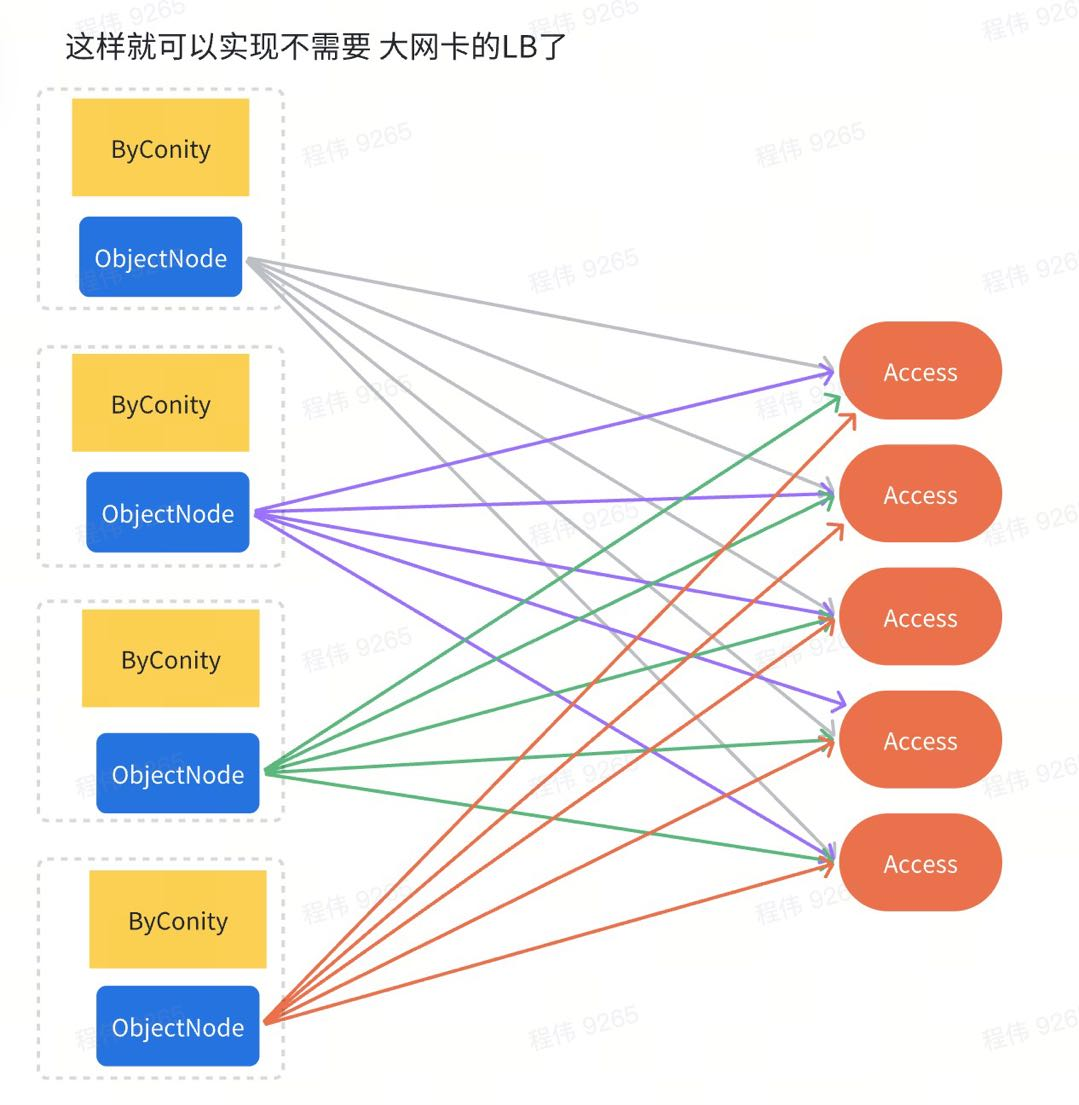
4、ObjectNode is deployed on the deployment nodes of ByConity to reduce the pressure on LB load balancing, and 80Gbps network effect can be achieved through node bandwidth aggregation without 100Gbps/s NIC.
Problems encountered and solutions
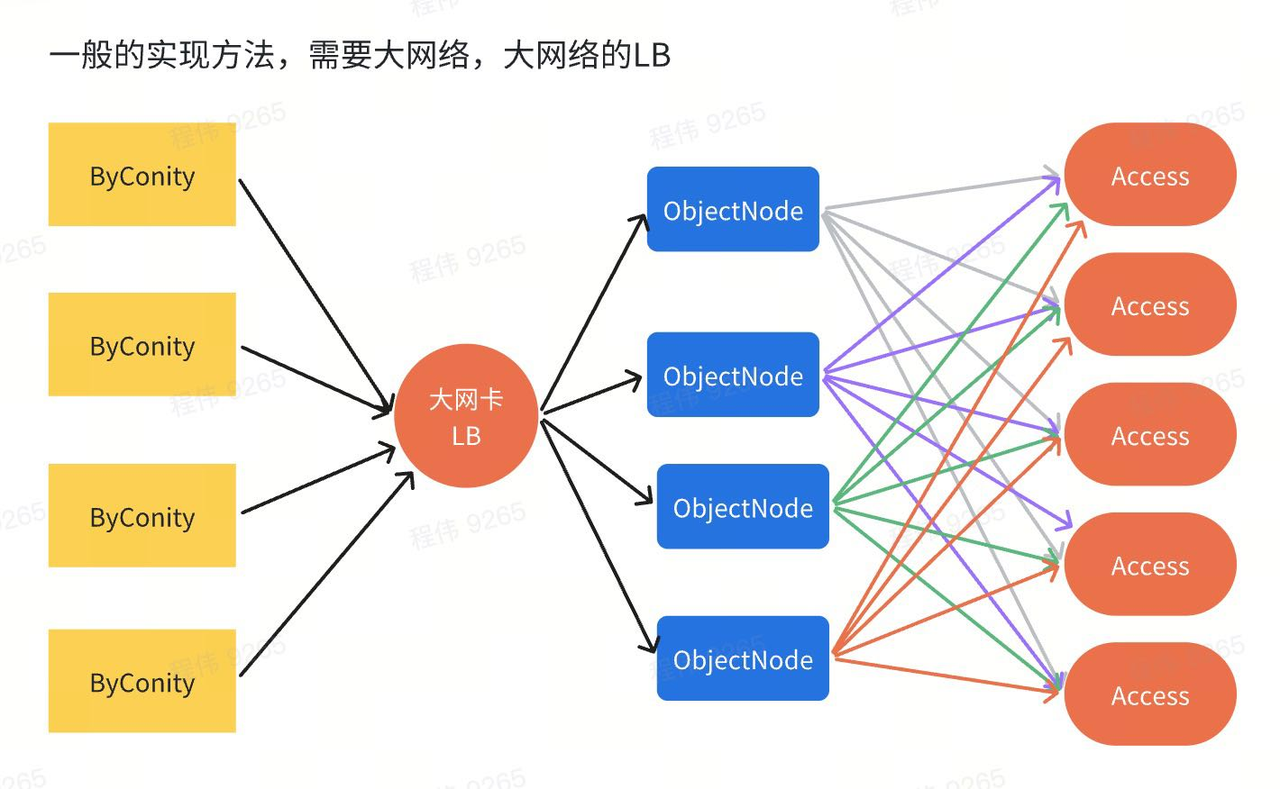
CubeFS Object Node service deployment: cubefs implements the S3 interface through objectNode. Since cubefs requires a lot of read bandwidth up to 64Gbps, and we do not have such a large LB machine, we have to deploy objectNode to the machine where ByConiy is located. Through direct load Access, the access effect of 8 nodes with 64Gbps bandwidth is achieved.
Empty directory optimization for CubeFS S3 scenario: CubeFS converts file prefixes into directories when creating object files, while ByConity creates a large number of prefixed objects. After deleting objects, the directory is not deleted, resulting in empty directories occupying a lot of metadata storage space. This problem is solved by adding code to delete the empty directory recursively in the delete interface of ObjectNode. (Since this is only an S3 case, only ObjectNode's S3 interface is modified.)
CubeFS erasure code strategy adjustment: Since we only have 10 storage nodes, using the 6+3 deployment mode, as long as two nodes fail, it will not be able to create a new volume, so we adjust to 5+3, so that after two nodes fail, we can still read and write data normally.
BlobNode kernel adjustment: Since BlobNode uses centos7 system, kernel 3.10.0 is too low, resulting in high average IO latency of nvem (more than 30 ms). After upgrading kernel 6.6.12, the average IO latency is reduced to 4ms.
Bandwidth constraints between multiple switches: Since the data storage node and the data read and write node are in different switches, we find that the download speed is stuck at 40Gbps. By excluding the bandwidth between the switches is full (10GB network is smooth to 40gbps), we can fully fill the network card by inserting the network cable of the data reading node and the data storage node into a switch. While the write scenario is not in great demand, it can be deployed on other switches.
future expectations
· Try the layered model of CubeFS to find a balance between performance and cost performance.
· Try the mode that ACCESS of CubeFS is integrated with ObjectNode through SDK to reduce latency and provide higher bandwidth on the basis of limited hardware.